




User-friendly SQL in BigQuery: Improving analytics, data quality, and security

TABLE OF CONTENTS
Profit.Store

130
Worldwide, approximately 7 million people actively use SQL for everyday data management and analysis. Whether you're a data engineer or an analyst, the way you interact with and use data to gain business insights is increasingly important in today's world.
BigQuery is an advanced cloud data warehouse that simplifies end-to-end analytics from start to finish. The platform includes data collection, preparation and analysis, as well as machine learning and SQL inference capabilities. Today, Google is introducing new SQL capabilities in BigQuery that extend the security and flexibility of data processing.
These new features include:
- Data quality schema operations: creating/modifying views with column descriptions, flexible column names, LOAD DATA SQL query.
- Secure data exchange and management: Authorised Stored Procedures.
- Flexible data analysis: LIKE ANY/SOME/ALL, ANY_VALUE (HAVING), index support for arrays and structures.
Advanced schema support for better data quality
Here's a look at how BigQuery's advanced schema support makes it easier to work with data. Google has extended schema support in BigQuery to make it easier for you to work with data.
Create or edit views with detailed column descriptions
Users provided valuable feedback on how to use views to share data with others. The ability to provide detailed column descriptions was an important feature. Google has extended this capability to views, allowing you to create or modify column descriptions directly from the CREATE/MODIFY statements of a view with column descriptions. Now you can easily control and document the data contained in your view without having to go into Terraform to create the view and fill in the column details.
-- Create a view with column description
CREATE VIEW view_name (column_name OPTIONS(description= “col x”)) AS…
-- Alter a view with column description
ALTER VIEW view_name ALTER COLUMN column_name
SET OPTIONS(description=“col x”)

Column naming flexibility
To make data more accessible and easier to work with, BigQuery has introduced additional options for naming columns in any language and using special characters such as ampersand (&) and percentage sign (%) in column names. This updated functionality is particularly useful for customers with data migration needs and international business data. Below is a partial list of the special characters that are now supported:
- Any letter in any language
- Any number in any language
- Any punctuation mark
- Any hyphen or dash
- Any character intended to be combined with another characterм
Examples of column names:
- `0col1`
- `姓名`
- `int-col`
##LOAD DATA SQL Query (GA)
Previously, we mainly used the load API to load data into BigQuery, which required an engineer's experience to learn the API and configuration. Since the introduction of LOAD DATA, we can load data using only SQL statements, which has greatly simplified our work and made it more compact and convenient.

Download data with flexible column names
LOAD DATA INTO dataset_name.table_name (`flexible column name 列` INT64) FROM FILES (uris=[“file_uri”], format=“CSV”);
Load into tables with renamed columns or columns deleted and added in a short period of time
--Create a table
CREATE TABLE dataset_name.table_name (col_name_1 INT64);
--Rename a column in the table
ALTER TABLE dataset_name.table_name RENAME COLUMN col_name_1 TO col_name_1_renamed;
--load data into a table with the renamed column
LOAD DATA INTO dataset_name.table_name
(col_name_1_renamed INT64)
FROM FILES (uris=[“file_uri”], format=“CSV”);
Load data into the table
LOAD DATA INTO dataset_name.table_name (col_name_1 INT64) PARTITION BY _PARTITIONDATE FROM FILES (uris=[“file_uri”], format=“CSV”);
Download or overwrite data on a selected partition
LOAD DATA INTO dataset_name.table_name PARTITIONS(_PARTITIONTIME = TIMESTAMP('2023-01-01')) (col_name_1 INT64) PARTITION BY _PARTITIONDATE FROM FILES (uris=[“file_uri”], format=“CSV”);
Secure data sharing and management
Permitted stored procedures
A stored procedure is a set of statements that can be called by other queries. If you need to share the results of stored procedure queries with certain users without giving them access to read the underlying table, the newly introduced Authorised Stored Procedure provides a secure way to share data.
How does it work?
- Data engineers create queries and grant access rights to authorised storage operations to specific groups of analysts. Analysts can then execute and view query results without having to access the underlying table.
- Analysts can use authorised stored procedures to create query objects such as tables, views, user-defined functions (UDFs) and so on. They can also call or perform Data Modification Language (DML) operations, within defined access rights, without having to access the underlying data.
Enhanced support for flexible data analysis
LIKE ANY/SOME/ALL
Analysts need to search for business information contained in columns of text, such as usernames, ratings or stock names. Now they can use LIKE ANY/LIKE ALL statements to check multiple patterns within a single query. This eliminates the need to create multiple queries using LIKE statements in combination with a WHERE clause.
The new LIKE ANY/SOME/ALL qualifiers allow you to filter rows by fields that match any or all of the specified patterns. This feature can make it much easier for analysts to filter data and generate insights based on their search criteria.
LIKE ANY (synonymous with LIKE SOME): You can filter rows by fields that match one or more of the specified patterns.
--Filter rows that match any patterns like 'Intend%', '%intention%'
WITH Words AS
(SELECT 'Intend with clarity.' as value UNION ALL
SELECT 'Secure with intention.' UNION ALL
SELECT 'Clarity and security.')
SELECT * FROM Words WHERE value LIKE ANY ('Intend%', '%intention%');
/*------------------------+
| value |
+------------------------+
| Intend with clarity. |
| Secure with intention. |
+------------------------*/
LIKE ALL: allows you to filter rows by fields that match all specified patterns
--Filter rows that match all patterns like '%ity%', ‘%ith’
WITH Words AS
(SELECT 'Intend with clarity.' as value UNION ALL
SELECT 'Secure with identity.' UNION ALL
SELECT 'Clarity and security.')
SELECT * FROM Words WHERE value LIKE ALL ('%ity%', ‘%ith’);
/*-----------------------+
| value |
+-----------------------+
| Intend with clarity. |
| Secure with identity. |
+-----------------------*/
ANY_VALUE (HAVING MAX | MIN) (GA)
Often customers are interested in values that relate to a maximum or minimum value in another column of the same row. For example, they may be looking for a product code. Previously, to get such data, you had to use a combination of array_agg() and order by() or last_value() in window functions. This was more complicated and less efficient, especially if there were duplicate records in the data.
Using the new qualifiers such as LIKE ANY, SOME and ALL makes the process much easier and more efficient. They allow you to easily filter data by specified conditions and get the results you need without the need for complex aggregation operations and windowing functions. This makes data analysis easier and allows you to get the insights you need with less effort.
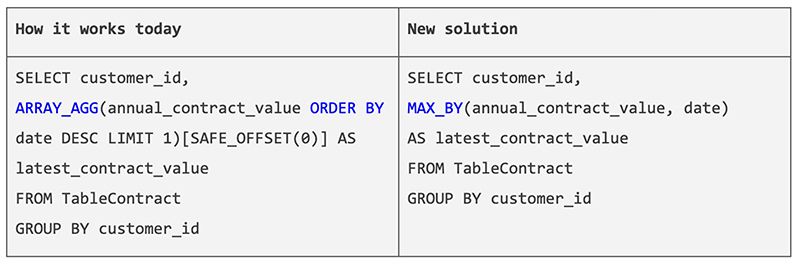
The ANY_VALUE(x HAVING MAX/MIN y) statement and its synonyms MAX_BY and MIN_BY allow you to easily retrieve data from a column that is associated with the maximum or minimum value of another column, making your SQL query more understandable and readable.
For example, if you need to find the last contract value for each customer, you can use the following query:
SELECT customer_id,
MAX_BY(anual_contract_value, date)
AS latest_contract_value
FROM TableContract
CROUP BY customer_id
Indexing support for arrays and structures (GA)
An array is an ordered set of values of the same data type. Currently, to access the elements of an array, you can use OFFSET(index) for zero indices (where the indices start at 0) or ORDINAL(index) for one indices (where the indices start at 1). For brevity, BigQuery now supports the use of a[n] as a synonym for a[OFFSET(n)]. This makes life easier for users who are already familiar with such access methods.
SELECT
some_numbers,
some_numbers[1] AS index_1, -- index starting at 0
some_numbers[OFFSET(1)] AS offset_1, -- index starting at 0
some_numbers[ORDINAL(1)] AS ordinal_1 -- index starting at 1
FROM Sequences
/*--------------------+---------+----------+-----------*
| some_numbers | index_1 | offset_1 | ordinal_1 |
+--------------------+---------+----------+-----------+
| [0, 1, 1, 2, 3, 5] | 1 | 1 | 0 |
| [2, 4, 8, 16, 32] | 4 | 4 | 2 |
| [5, 10] | 10 | 10 | 5 |
A structure is a data type that consists of ordered fields of different data types. Today, when a structure contains anonymous fields or fields with the same name, accessing the values of these fields can be a challenge. Similar to the approach used for arrays, we use OFFSET(index) for zero indices (where indices start at 0) and ORDINAL(index) for one indices (where indices start at 1). This index support allows you to easily retrieve field values at a selected position in the structure, simplifying your work with data.

More BigQuery features that are now GA
Here are some of the BigQuery features that have recently moved from preview to general availability (GA) and are now supported on Google Cloud.
Dropping/renaming a column
If you want to delete or rename a column, you can use the DROP COLUMN or RENAME COLUMN command directly, without any additional metadata processing.
Google Analytics has extended its support for copying tables. If you have a table with a column that was previously renamed or deleted, you can now create a copy of that table using the CREATE TABLE COPY statement or run a copy job with the updated information.
Comparing strings case insensitive
You can sort and compare strings without regard to case by using the 'and:ci' parameter. This means that the characters [A,a] are treated as equivalent and perceived as the same in string value operations, and the characters [B,b] are taken into account after them. In the Analytics (GA) environment, Google has extended this capability to aggregate functions (MIN, MAX, COUNT DISTINCT), materialised views, business intelligence systems and more.
SHARE

OTHER ARTICLES BY THIS AUTHOR
Get the most exciting news first!
Expert articles, interviews with entrepreneurs and CEOs, research, analytics, and service reviews: be up to date with business and technology news and trends. Subscribe to the newsletter!
By clicking “Subscribe” you agree to Privacy Policy and consent using your contact data for newsletter purposes
OR FOLLOW ON:
