




Зручний SQL у BigQuery: Підвищення аналітики, якості та безпеки даних

ЗМІСТ
Profit.Store

297
По всьому світу приблизно 7 мільйонів осіб активно користуються SQL для повсякденного управління і аналізу даних. Незалежно від вашої спеціалізації - чи то ви інженер з обробки даних, чи аналітик, - спосіб, яким ви взаємодієте та використовуєте дані з метою отримання бізнес-інсайтів, стає надзвичайно важливим у наш час.
BigQuery - це передове хмарне сховище даних, яке допомагає спростити наскрізну аналітику від початку до кінця. Ця платформа включає в себе збір, підготовку, аналіз даних, а також можливість машинного навчання та отримання висновків за допомогою SQL. Сьогодні, компанія Google представляє нові можливості SQL у BigQuery, які розширюють безпеку та гнучкість обробки даних.
Ці нові можливості включають:
- Операції зі схемами поліпшення якості даних: створення/зміна представлень з описами стовпців, гнучка назва стовпця, SQL-запит LOAD DATA.
- Безпечний обмін даними та управління ними: авторизовані збережені процедури.
- Гнучкий аналіз даних: LIKE ANY/SOME/ALL, ANY_VALUE (HAVING), підтримка індексів для масивів та структур.
Розширення підтримки схем для кращої якості даних
Нижче ми покажемо розширену підтримку схем у BigQuery, яка спрощує роботу з даними. Google розширив підтримку схем у BigQuery, щоб полегшити вам роботу з даними.
Створення або редагування подань із детальними описами стовпців
Користувачі надали цінний фідбек щодо використання подань для забезпечення доступу до даних для інших користувачів. Можливість надавати докладні описи, що містяться у стовпцях, стало важливою функцією. Google розширив цю можливість для подань, що дозволяє безпосередньо створювати або змінювати описи стовпців, використовуючи оператори СТВОРЕННЯ/ЗМІНИ подання з описами стовпців. Тепер ви можете легко контролювати та документувати дані, що містяться у вашому поданні, без необхідності втручання у Terraform для створення подання та заповнення деталей стовпців.
-- Create a view with column description
CREATE VIEW view_name (column_name OPTIONS(description= “col x”)) AS…
-- Alter a view with column description
ALTER VIEW view_name ALTER COLUMN column_name
SET OPTIONS(description=“col x”)

Гнучкість назви стовпця
З метою полегшення доступності та зручності роботи з даними, BigQuery вніс додаткові можливості для іменування стовпців будь-якими мовами світу та використання спеціальних символів, таких як амперсанд (&) та знак відсотка (%), у назвах стовпців. Ця оновлена функціональність особливо корисна для клієнтів з потребами у міграції даних та міжнародними бізнес-даними. Нижче наведено лише частковий список спеціальних символів, які тепер підтримуються:
- Будь-яка літера на будь-якій мові
- Будь-який цифровий символ будь-якою мовою
- Будь-який знак пунктуації
- Будь-який дефіс або тире
- Будь-який символ, призначений для поєднання з іншим символом
Приклади назв стовпців:
- `0col1`
- `姓名`
- `int-col`
LOAD DATA SQL-запит (GA)
Раніше ми в основному використовували API load для завантаження даних у BigQuery, що вимагало досвіду інженера для вивчення API та конфігурації. З моменту запуску LOAD DATA ми можемо завантажувати дані лише за допомогою операторів SQL, що значно спростило роботу, зробило її компактнішою та зручнішою.

Завантажуйте дані з гнучкою назвою стовпця
LOAD DATA INTO dataset_name.table_name (`flexible column name 列` INT64) FROM FILES (uris=[“file_uri”], format=“CSV”);
Завантаження в таблиці з перейменованими стовпчиками або стовпчиками, видаленими та доданими за короткий час
--Create a table
CREATE TABLE dataset_name.table_name (col_name_1 INT64);
--Rename a column in the table
ALTER TABLE dataset_name.table_name RENAME COLUMN col_name_1 TO col_name_1_renamed;
--load data into a table with the renamed column
LOAD DATA INTO dataset_name.table_name
(col_name_1_renamed INT64)
FROM FILES (uris=[“file_uri”], format=“CSV”);
Завантажте дані в таблицю
LOAD DATA INTO dataset_name.table_name (col_name_1 INT64) PARTITION BY _PARTITIONDATE FROM FILES (uris=[“file_uri”], format=“CSV”);
Завантажити дані в один вибраний розділ або перезаписати його
LOAD DATA INTO dataset_name.table_name PARTITIONS(_PARTITIONTIME = TIMESTAMP('2023-01-01')) (col_name_1 INT64) PARTITION BY _PARTITIONDATE FROM FILES (uris=[“file_uri”], format=“CSV”);
Безпечніший обмін та керування даними
Авторизовані збережені процедури
Збережена процедура представляє собою набір операторів, які можна викликати з інших запитів. Якщо вам необхідно поділитися результатами запитів зі збережених процедур із певними користувачами, не надаючи їм доступ до читання базової таблиці, то нещодавно введена авторизована збережена процедура створює безпечний спосіб надання доступу до даних.
Як це працює?
- Інженери даних формують запити та надають права доступу для авторизованих процедур зберігання для конкретних груп аналітиків. Після цього аналітики можуть запускати та переглядати результати запитів без необхідності отримувати доступ до базової таблиці.
- Аналітики можуть використовувати авторизовані збережені процедури для створення об'єктів запитів, таких як таблиці, подання, функції з користувальницьким визначенням (UDF) і так далі. Вони також мають можливість викликати або виконувати операції DML (модифікації даних мовою запитів), дотримуючись встановлених прав доступу і без необхідності отримувати доступ до основних даних.
Розширена підтримка для гнучкого аналізу даних
LIKE ANY/SOME/ALL
Аналітикам доводиться виконувати пошук бізнес-інформації, яка міститься в текстових стовпцях, таких як імена користувачів, відгуки або назви запасів. Зараз вони можуть використовувати оператори LIKE ANY/LIKE ALL для перевірки декількох шаблонів у рамках одного запиту. Це дозволяє уникнути необхідності створювати кілька запитів з операторами LIKE у комбінації з умовою WHERE.
За допомогою нових кваліфікаторів LIKE ANY/SOME/ALL ви здатні фільтрувати рядки за полями, які відповідають будь-якому або всім заданим шаблонам. Ця можливість може значно полегшити завдання аналітиків при фільтрації даних та створенні інсайтів на основі їхніх критеріїв пошуку.
LIKE ANY (синонім LIKE SOME): ви можете відфільтрувати рядки за полями, які відповідають одному або декільком вказаним шаблонам.
--Filter rows that match any patterns like 'Intend%', '%intention%'
WITH Words AS
(SELECT 'Intend with clarity.' as value UNION ALL
SELECT 'Secure with intention.' UNION ALL
SELECT 'Clarity and security.')
SELECT * FROM Words WHERE value LIKE ANY ('Intend%', '%intention%');
/*------------------------+
| value |
+------------------------+
| Intend with clarity. |
| Secure with intention. |
+------------------------*/
LIKE ALL: ви можете відфільтрувати рядки за полями, які відповідають усім зазначеним шаблонам
--Filter rows that match all patterns like '%ity%', ‘%ith’
WITH Words AS
(SELECT 'Intend with clarity.' as value UNION ALL
SELECT 'Secure with identity.' UNION ALL
SELECT 'Clarity and security.')
SELECT * FROM Words WHERE value LIKE ALL ('%ity%', ‘%ith’);
/*-----------------------+
| value |
+-----------------------+
| Intend with clarity. |
| Secure with identity. |
+-----------------------*/
ANY_VALUE (HAVING MAX | MIN) (GA)
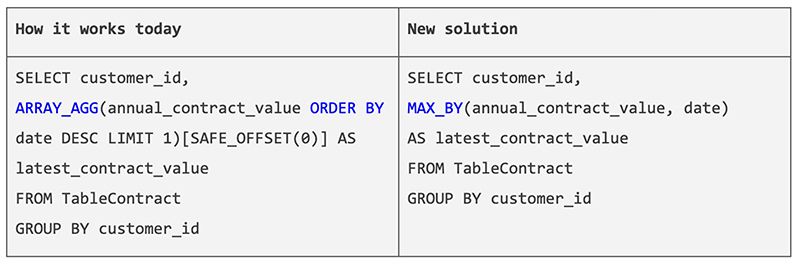
Часто клієнти цікавляться значеннями, які пов'язані з максимальним або мінімальним значенням в іншому стовпці того ж рядка. Наприклад, вони можуть шукати код товару. Раніше для отримання таких даних потрібно було використовувати комбінацію функцій array_agg() та order by () або last_value() у віконних функціях. Це було складніше і менш ефективно, особливо, коли в даних були повторюючі записи.
Використання нових кваліфікаторів, таких як LIKE ANY, SOME і ALL, значно спрощує та підвищує ефективність процесу. Завдяки ним, ви можете легко фільтрувати дані за вказаними умовами, одержуючи потрібні результати без потреби в складних операціях агрегації та віконних функцій. Це робить аналіз даних більш простим і дає змогу отримувати необхідні інсайти з меншими зусиллями.
За допомогою операторів ANY_VALUE(x HAVING MAX/MIN y), а також її синонімів MAX_BY і MIN_BY, ви можете легко отримувати дані зі стовпця, пов'язаного з максимальним або мінімальним значенням іншого стовпця, що робить SQL-запит більш зрозумілим та читабельним.
Наприклад, якщо вам потрібно знайти останню вартість контракту для кожного споживача, ви можете використовувати такий запит:
SELECT customer_id,
MAX_BY(anual_contract_value, date)
AS latest_contract_value
FROM TableContract
CROUP BY customer_id
Підтримка індексів для масивів і структур (GA)
Масив - це впорядкований набір значень одного типу даних. На сьогоднішній день, для доступу до елементів масиву ви можете використовувати OFFSET(index) для нульових індексів (де індекси починаються з 0) або ORDINAL(index) для одиничних індексів (де індекси починаються з 1). З метою забезпечення лаконічності, BigQuery тепер підтримує використання a[n] як синонім a[OFFSET(n)]. Це спрощує роботу користувачам, які вже ознайомлені з такими способами доступу.
SELECT
some_numbers,
some_numbers[1] AS index_1, -- index starting at 0
some_numbers[OFFSET(1)] AS offset_1, -- index starting at 0
some_numbers[ORDINAL(1)] AS ordinal_1 -- index starting at 1
FROM Sequences
/*--------------------+---------+----------+-----------*
| some_numbers | index_1 | offset_1 | ordinal_1 |
+--------------------+---------+----------+-----------+
| [0, 1, 1, 2, 3, 5] | 1 | 1 | 0 |
| [2, 4, 8, 16, 32] | 4 | 4 | 2 |
| [5, 10] | 10 | 10 | 5 |
Структура - це тип даних, який складається з впорядкованих полів різних типів даних. На сьогоднішній день, у випадку, коли в структурі присутні анонімні поля або поля з однаковими іменами, доступ до значень цих полів може стати складним завданням. Аналогічно до підходу, використовуваного для масивів, ми використовуємо OFFSET(index) для нульових індексів (де індекси починаються з 0) та ORDINAL(index) для одиничних індексів (де індекси починаються з 1). Ця підтримка індексів дозволяє легко отримувати значення полів на вибраній позиції в структурі, спрощуючи роботу з даними.

Більше функцій BigQuery, які тепер є GA
Ось деякі з функцій BigQuery, які нещодавно перейшли з попереднього перегляду (Preview) у статус загального доступу (General Availability, GA) і тепер підтримуються в Google Cloud:
Видалення/перейменування стовпця
Якщо ви плануєте видалити або перейменувати стовпець, ви можете безпосередньо використовувати команду DROP COLUMN або RENAME COLUMN, що не потребує додаткових витрат на обробку метаданих.
У Google Analytics розширено можливості щодо підтримки копіювання таблиць. Тепер, якщо у вас є таблиця зі стовпцем, який було раніше перейменовано або вилучено, ви маєте можливість створити копію цієї таблиці за допомогою оператора CREATE TABLE COPY або запустити завдання на копіювання з оновленою інформацією.
Порівняння рядків без урахування регістру
У вас є можливість проводити сортування та порівняння рядків незалежно від регістру, використовуючи параметр 'und:ci'. Це означає, що символи [A,a] розглядаються як еквівалентні та сприймаються однаковими в операціях з рядковими значеннями, і символи [B, b] будуть враховуватися після них. У аналітичному середовищі (GA) Google розширив цю можливість на агрегатні функції (MIN, MAX, COUNT DISTINCT), матеріалізовані представлення, бізнес-інтелект-системи та багато іншого.
ПОДІЛИТИСЯ

ІНШІ СТАТТІ ВІД АВТОРА
Дізнавайтеся першими про найцікавіше!
Експертні статті, інтерв’ю з підприєцями і СЕО, дослідження, аналітика і огляди сервісів – будьте у курсі новин і трендів у бізнесі та технологіях. Підписуйтеся на розсилку!
Натискаючи «Підписатися», ви погоджуєтеся з Політикою конфіденційності та даєте згоду на використання ваших контактних даних для розсилки новин
АБО СЛІДКУЙ ЗА НАМИ У:
