




Огляд BigQuery: інтерфейс сервісу, основні плюси та мінуси системи

ЗМІСТ
Profit.Store

611
BigQuery - це хмарне сховище даних, яке не просто збирає структуровані дані з різноманітних джерел, але й надає можливості для їхнього глибокого аналізу. Таким чином, BigQuery можна охарактеризувати як аналітичну базу даних, призначену для виконання запитів і надання обширного уявлення про дані.
BigQuery ефективно інтегрує функціональність програмного забезпечення для роботи з електронними таблицями, на зразок Google Sheets, і можливості систем управління базами даних, як MySQ.
Чому потрібно використовувати BigQuery
Однією з ключових переваг вибору BigQuery є його здатність ефективно обробляти аналітичні запити. BigQuery забезпечує потужні можливості для проведення складних аналітичних запитів на великі обсяги даних. "QUERY" у цьому контексті означає виконання запитів даних, що можуть включати дії, такі як обчислення, модифікація, об'єднання та інші види маніпуляцій з даними.
У Google Sheets існує функція QUERY, яка дозволяє запитувати набори даних, що може бути корисно для створення різноманітних звітів та діаграм, заснованих на малих і середніх наборах даних. Проте, жодна програма для роботи з електронними таблицями, включаючи навіть таку популярну як Excel, не спроможна ефективно обробляти величезні набори даних, що містять мільйони рядків, і виконувати складні запити на них. Саме тут вирішальну роль відіграє BigQuery, що здатний справлятися з подібними завданнями.
BigQuery спеціалізується на виконанні аналітичних запитів, які виходять за рамки базових операцій CRUD (Створення, Читання, Оновлення, Видалення). Це інструмент, який забезпечує високу пропускну спроможність для обробки великих обсягів даних. Однак, BigQuery не призначений бути універсальним рішенням для всіх сценаріїв роботи з базами даних і не є прямою заміною реляційним базам даних. Він вирішує специфічні потреби в аналізі великих даних і слід використовувати у поєднанні з іншими інструментами та платформами для повноцінного управління даними.
Як використовувати Google BigQuery
Ще однією переконливою причиною для розгляду BigQuery як рішення для роботи з даними є те, що він є повністю хмарним сервісом. Це означає, що вам не доведеться займатися встановленням та налаштуванням будь-якого додаткового програмного забезпечення. Google відповідає за управління всією інфраструктурою, звільняючи вас від турбот про технічне обслуговування. Все, що потрібно, – це налаштувати BigQuery.
Налаштування BigQuery
Перший крок
Починаємо з Google Cloud Platform. Потрібно вибрати свою країну і прийняти Умови використання.
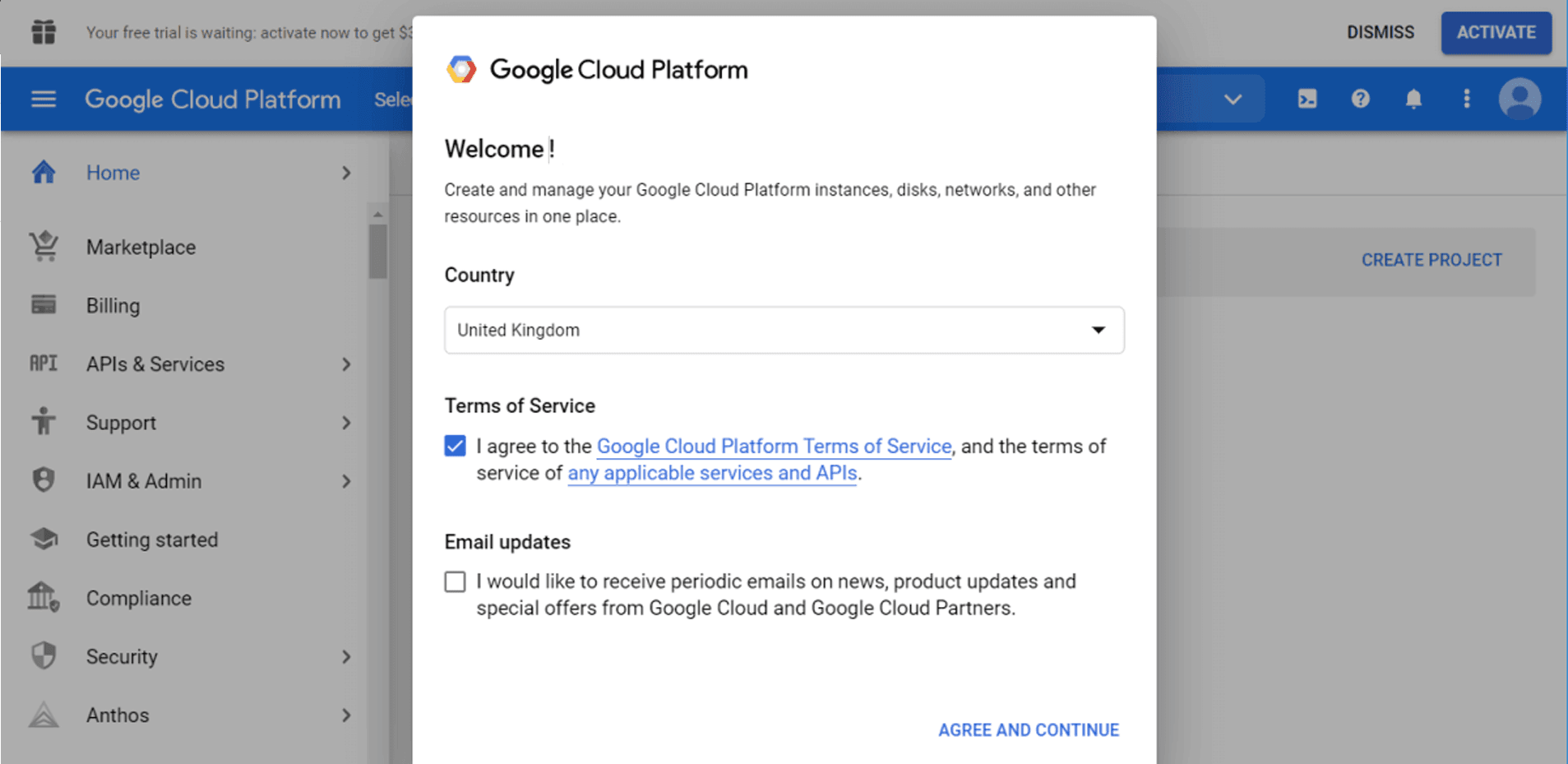
Після цього перейдіть у BigQuery - ви можете використовувати або панель пошуку, або знайти її вручну в лівому меню.
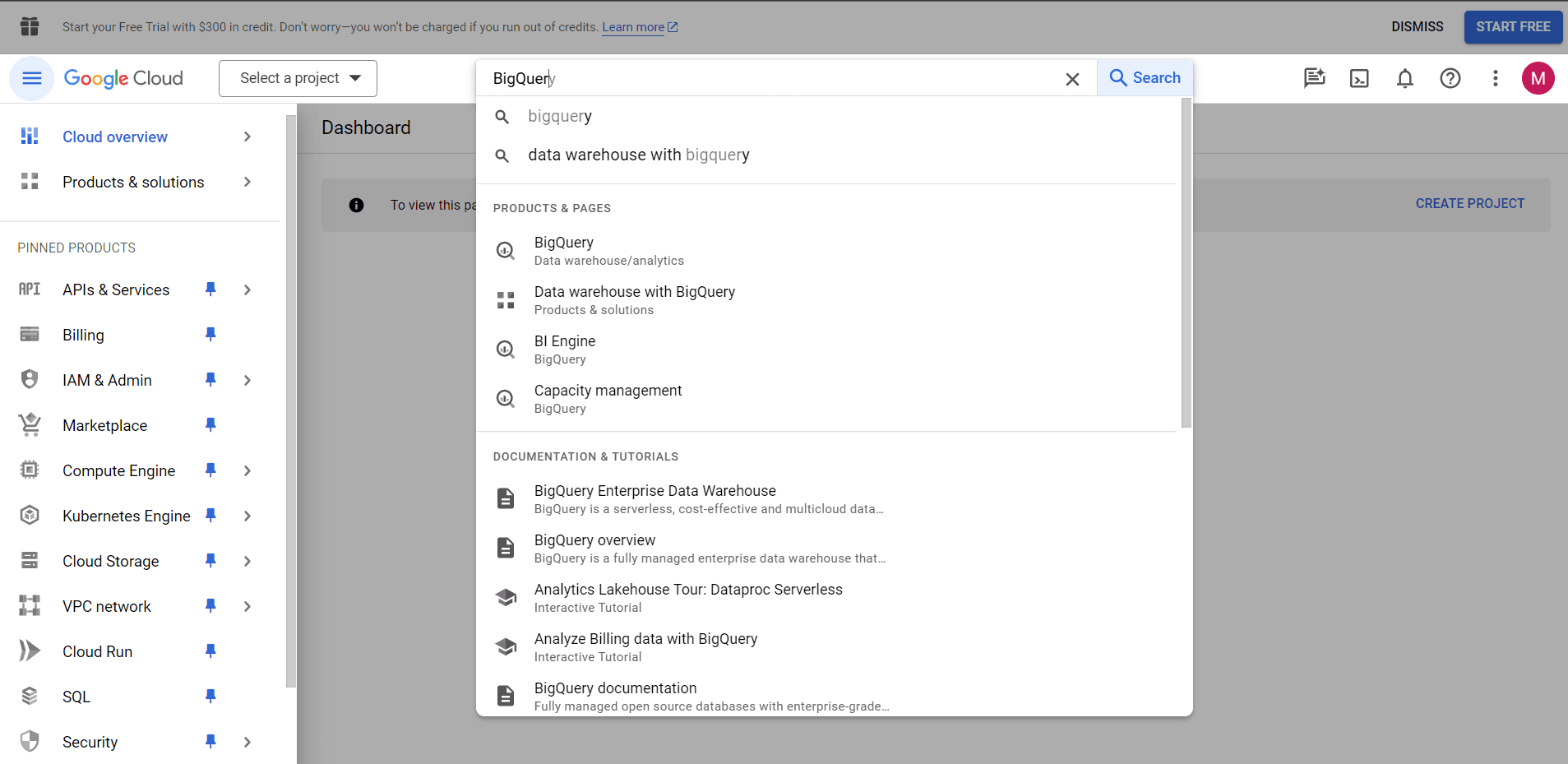
Створення проєкту
Ось який вигляд має BigQuery під час першого відвідування.
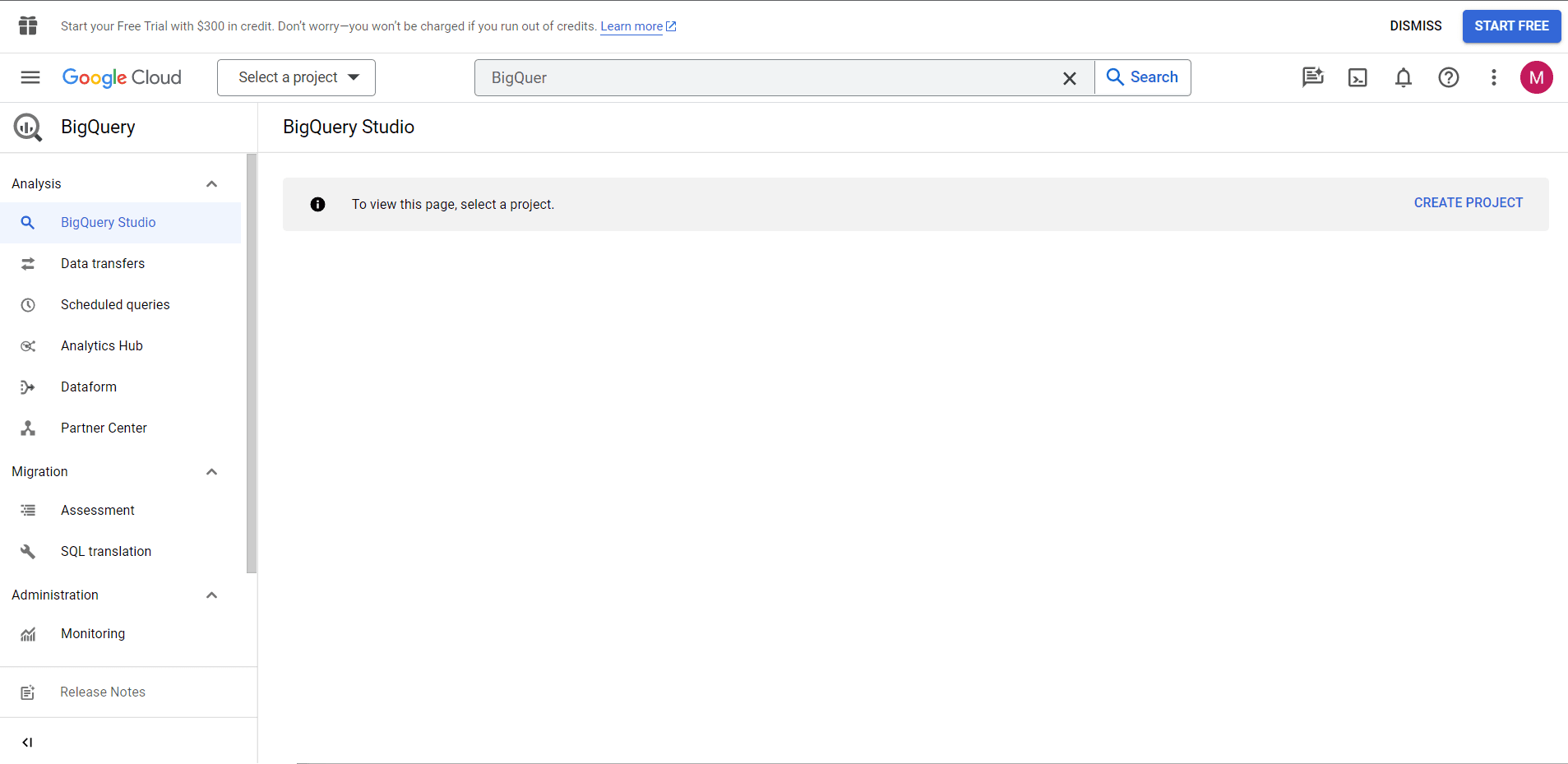
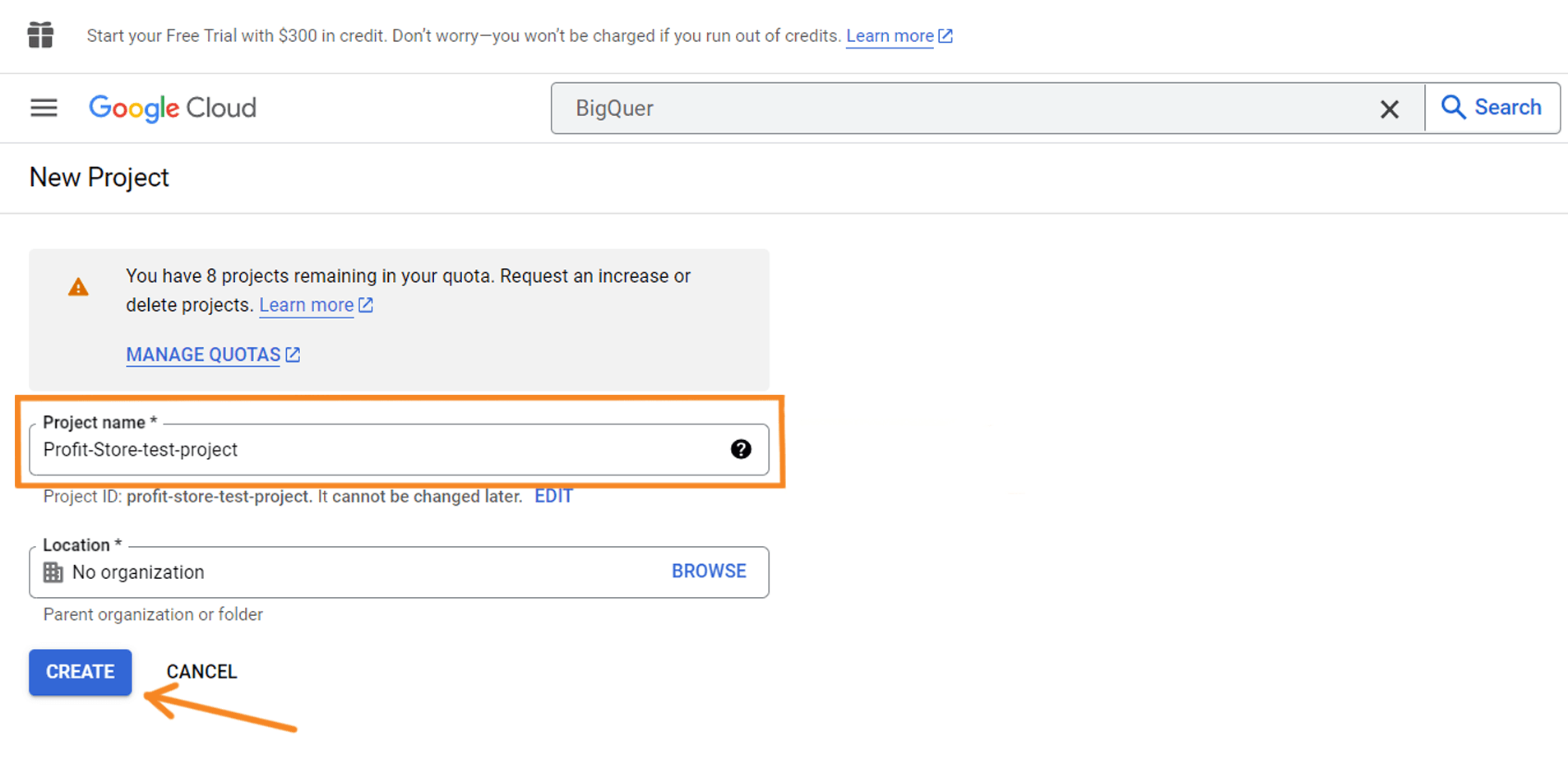
Натисніть кнопку "CREATE PROJECT", щоб створити проєкт. Назвіть свій проєкт, за необхідності виберіть організацію і натисніть "CREATE".
Тепер вас офіційно вітають у BigQuery.
SANDBOX BigQuery
Використання SANDBOX або "пісочниці" у контексті BigQuery означає користування обліковим записом у середовищі для тестування, де немає потреби вводити платіжні дані. Цей режим дозволяє використовувати BigQuery безкоштовно з певними обмеженнями: отримуєте 10 ГБ активного сховища і 1 ТБ обсягу даних, що обробляються запитами на місяць. Однак варто відзначити, що при використанні SANDBOX режиму, таблиці, створені в обліковому записі, матимуть термін дії, який закінчується через 60 днів після їх створення.
Другий варіант пропонує активувати безкоштовну пробну версію BigQuery, яка має відмінності від режиму "пісочниця". Основна різниця полягає в тому, що для активації пробної версії необхідно ввести платіжні дані. Виконавши цю вимогу, користувачі отримають 300 доларів у вигляді хмарних кредитів, які можна використовувати для доступу до ширшого спектру сервісів Google Cloud, включаючи BigQuery.
У Google BigQuery ми будемо використовувати варіант "пісочниці".
Створити набір даних у BigQuery
Додамо дані в BigQuery, щоб перевірити, як це працює. Натисніть на потрібний проєкт, а потім на "Create dataset".
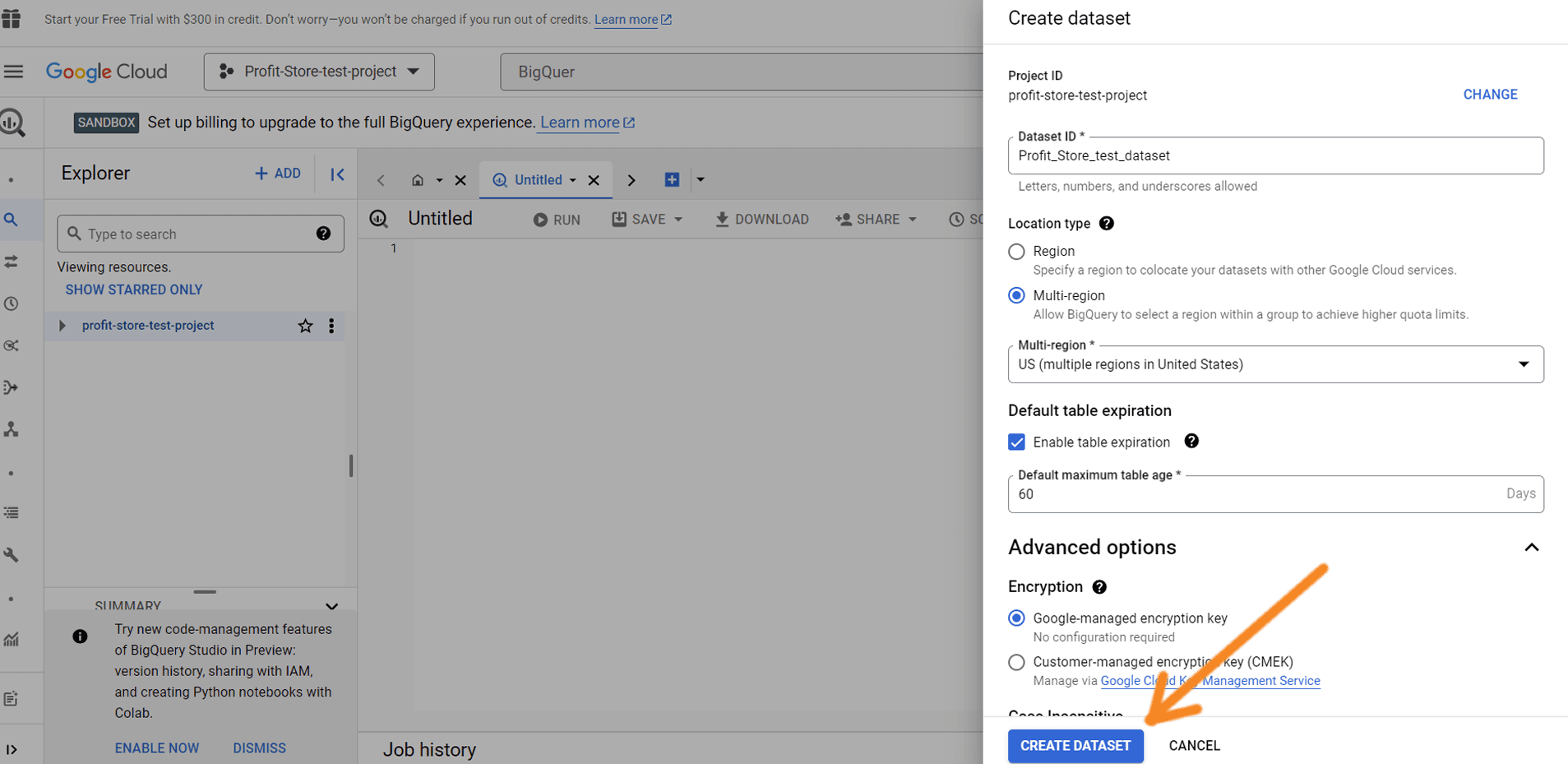
Призначте ідентифікатор набору даних - можна вводити букви і цифри. За необхідності можна вибрати розташування даних, а також термін дії таблиці (до 60 днів) і шифрування. Після цього натисніть "Create dataset".
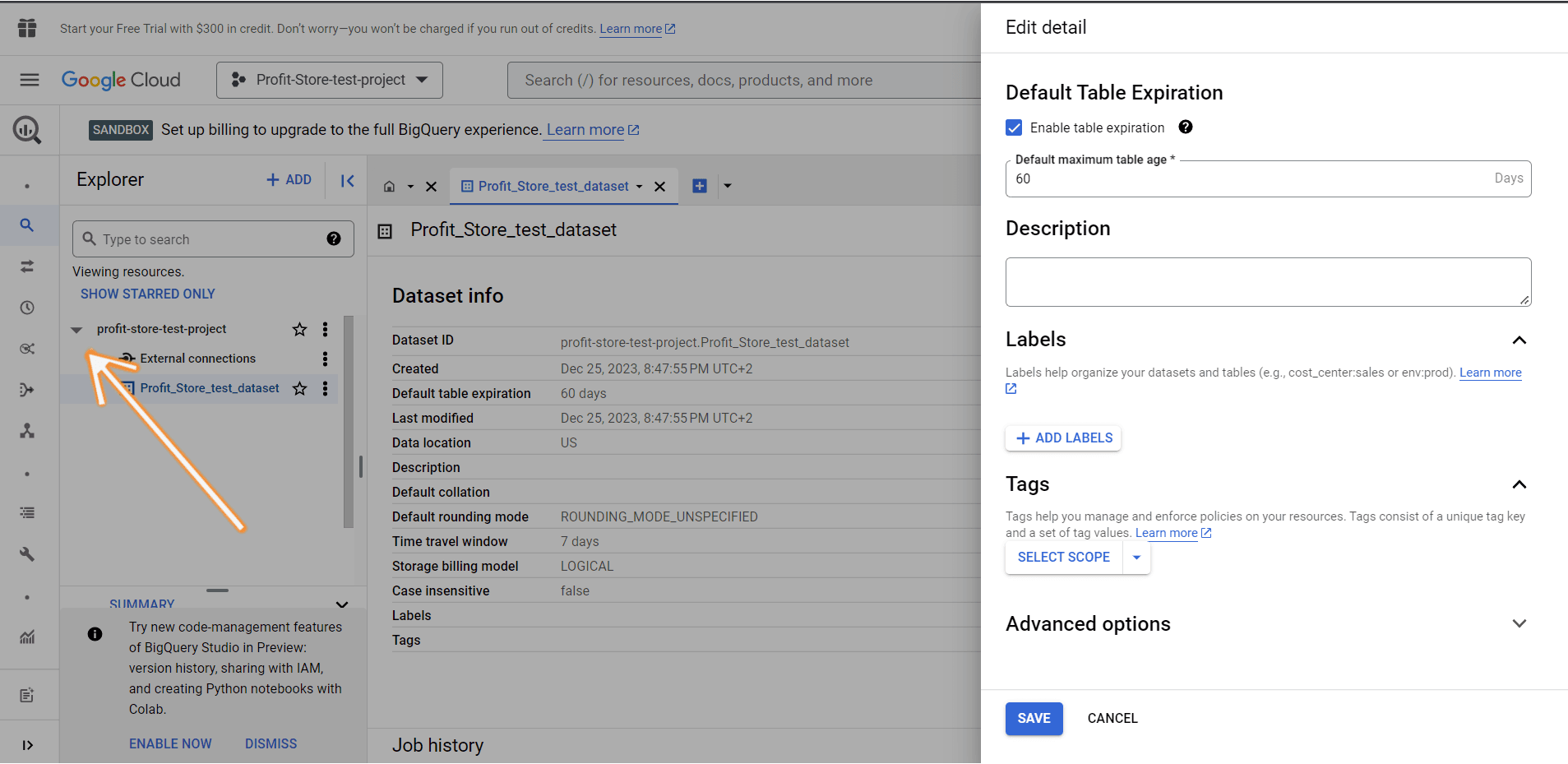
Створено новий набір даних. Ви можете знайти його, натиснувши кнопку "Розгорнути вузол" поруч із назвою проєкту:
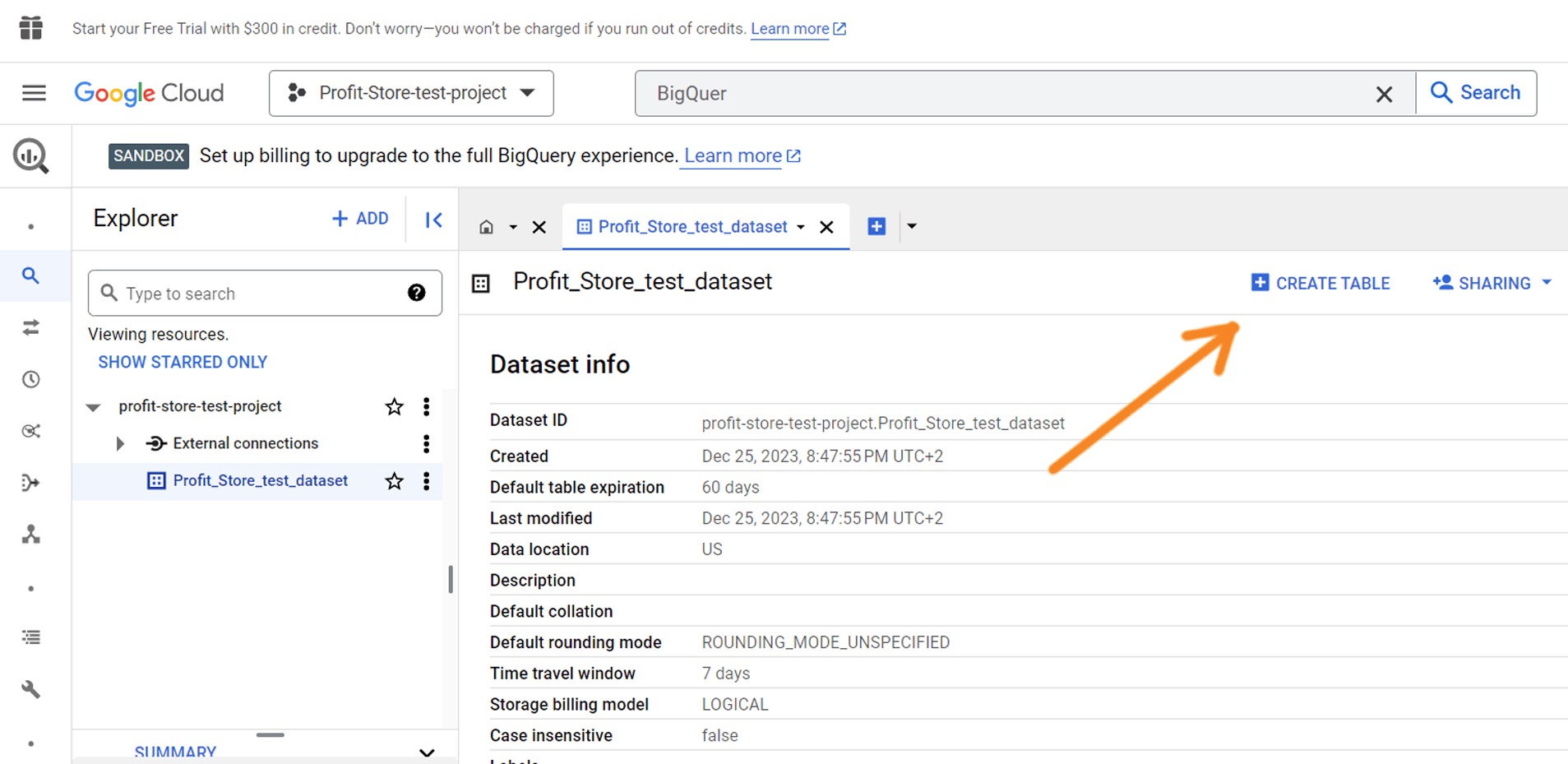
Наступним кроком буде створення таблиці в наборі даних. Натисніть на кнопку "Create table":
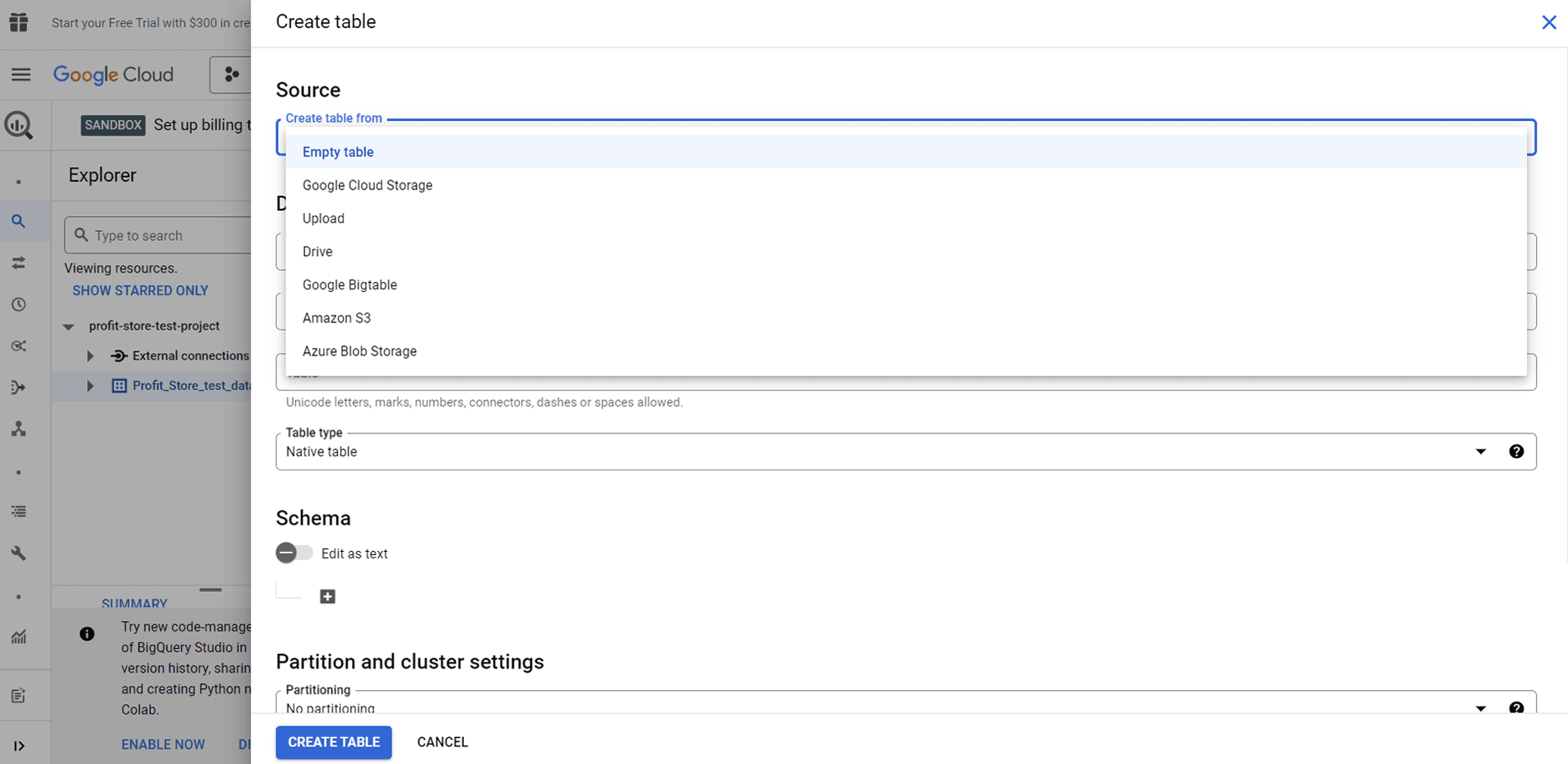
Тут є кілька варіантів:
- Створити порожню таблицю (Empty table) і заповнити її вручну.
- Завантажити (Upload) таблицю з пристрою в одному з підтримуваних форматів.
- Імпортувати таблицю з Google Cloud Storage або Google Диска (Drive).
- Імпортувати таблицю з Google Cloud Bigtable через інтерфейс командного рядка.
Формати файлів, які можна імпортувати в BigQuery
Табличні дані можна легко завантажити в BigQuery в таких форматах:
- CSV
- JSONL (лінії JSON)
- Avro
- Parquet
- ORC
- Google Sheets (тільки для Google Диска)
- Резервне копіювання хмарного сховища даних (тільки для хмарного сховища Google)
Примітка: не можна імпортувати файли Excel безпосередньо в BigQuery. Для цього потрібно або перетворити файл Excel в CSV, або перетворити Excel в Google Таблиці, а потім завантажити в BigQuery.
Завантажити дані CSV у BigQuery
Після натискання на кнопку "Create table", необхідно виконати такі кроки:
- Вибрати джерело - "Upload"
- Вибрати файл - натиснути "Огляд" і вибрати файл CSV на своєму пристрої.
- Формат файлу - вибрати "CSV", але зазвичай система визначає формат файлу автоматично.
- Ввести ім'я таблиці.
- Встановити прапорець автовизначення схеми "Auto detect".
- Натиснути "Create table".

Так виглядає основний потік. Крім того, можна визначити параметри розділу (для поділу таблиці на більш дрібні сегменти), параметри кластера (для організації даних на основі вмісту зазначених стовпців), а також налаштувати додаткові параметри "Advanced options".
Примітка. Функція попереднього перегляду таблиць дає змогу попередньо переглядати таблиці, що зберігаються у BigQuery. Наприклад, коли завантажуєте CSV, він зберігається у BigQuery - ви побачите аркуш попереднього перегляду.
Імпорт даних з Google Таблиць у BigQuery
Багато з вас зацікавлені в тому, як імпортувати таблиці з Google Sheets у BigQuery. Процес досить простий, хоча і містить деякі специфічні кроки. Ось основні етапи, які потрібно виконати:
- Натиснути кнопку "Create table":
- Вибрати джерело - "Drive"
- Вибрати Drive URI - вставити URL-адресу електронної таблиці Google Таблиць.
- Формат файлу - вибрати "Google Sheets".
- Діапазон аркушів - вказати аркуш і діапазон даних для імпорту. Якщо залишите це поле порожнім, BigQuery витягуватиме дані з першого аркуша електронної таблиці.
- Ввести ім'я таблиці.
- Встановити прапорець автовизначення схеми "Auto detect".
- Натиснути "Create table".
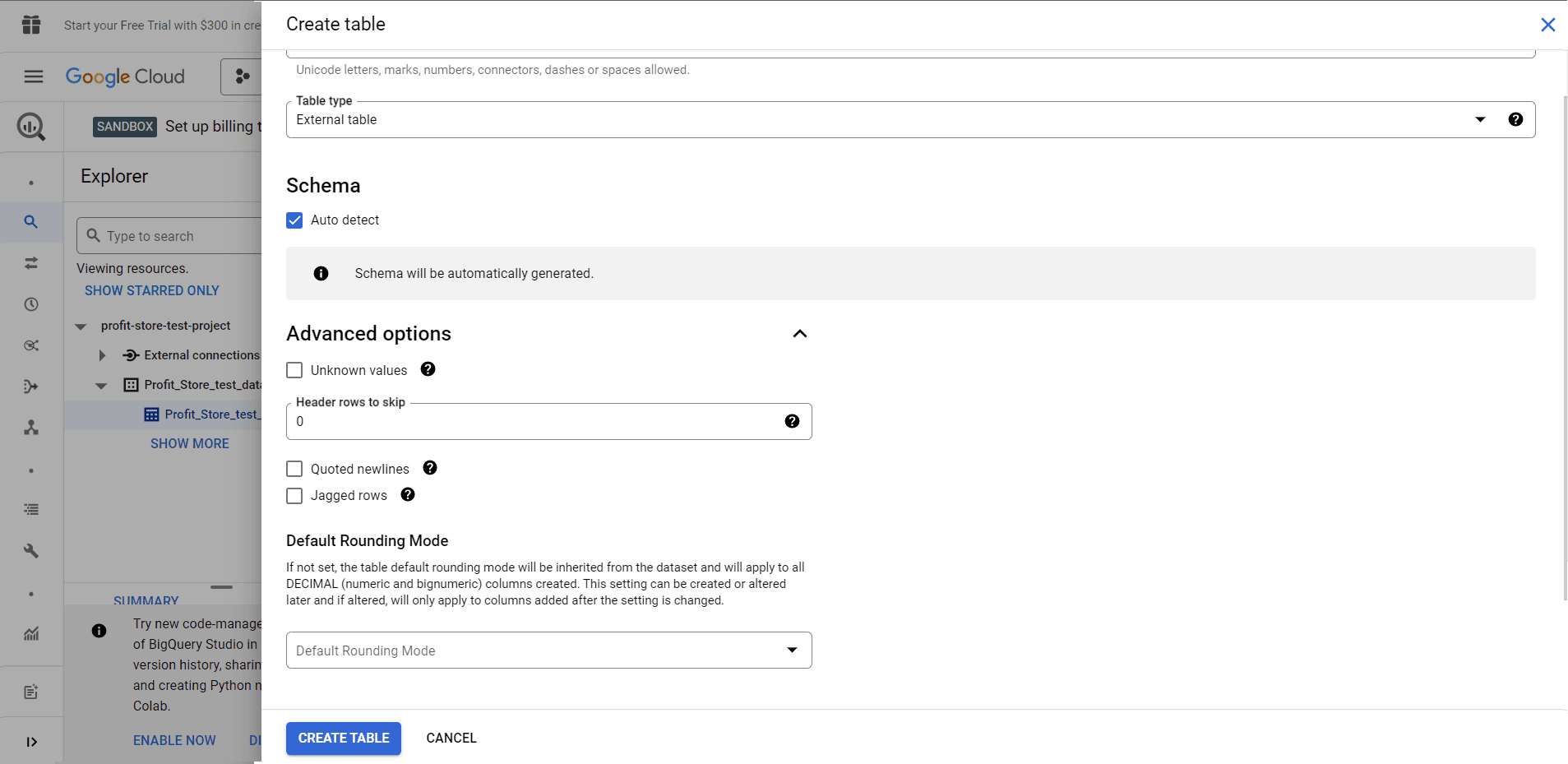
Можливо, буде цікаво як налаштувати додаткові параметри "Advanced options", оскільки вони дають змогу:
- Пропускати рядки зі значеннями стовпців, що не відповідають схемі.
- Пропускати певну кількість рядків зверху.
- Дозволити включення нових рядків, що містяться в цитованих розділах даних.
- Дозволити приймання рядків, у яких відсутні завершальні необов'язкові стовпці.
- Вибрати рішення для управління ключами шифрування.
Після натискання "Create table" у BigQuery, вибраний аркуш з Google Sheets буде імпортовано в BigQuery.
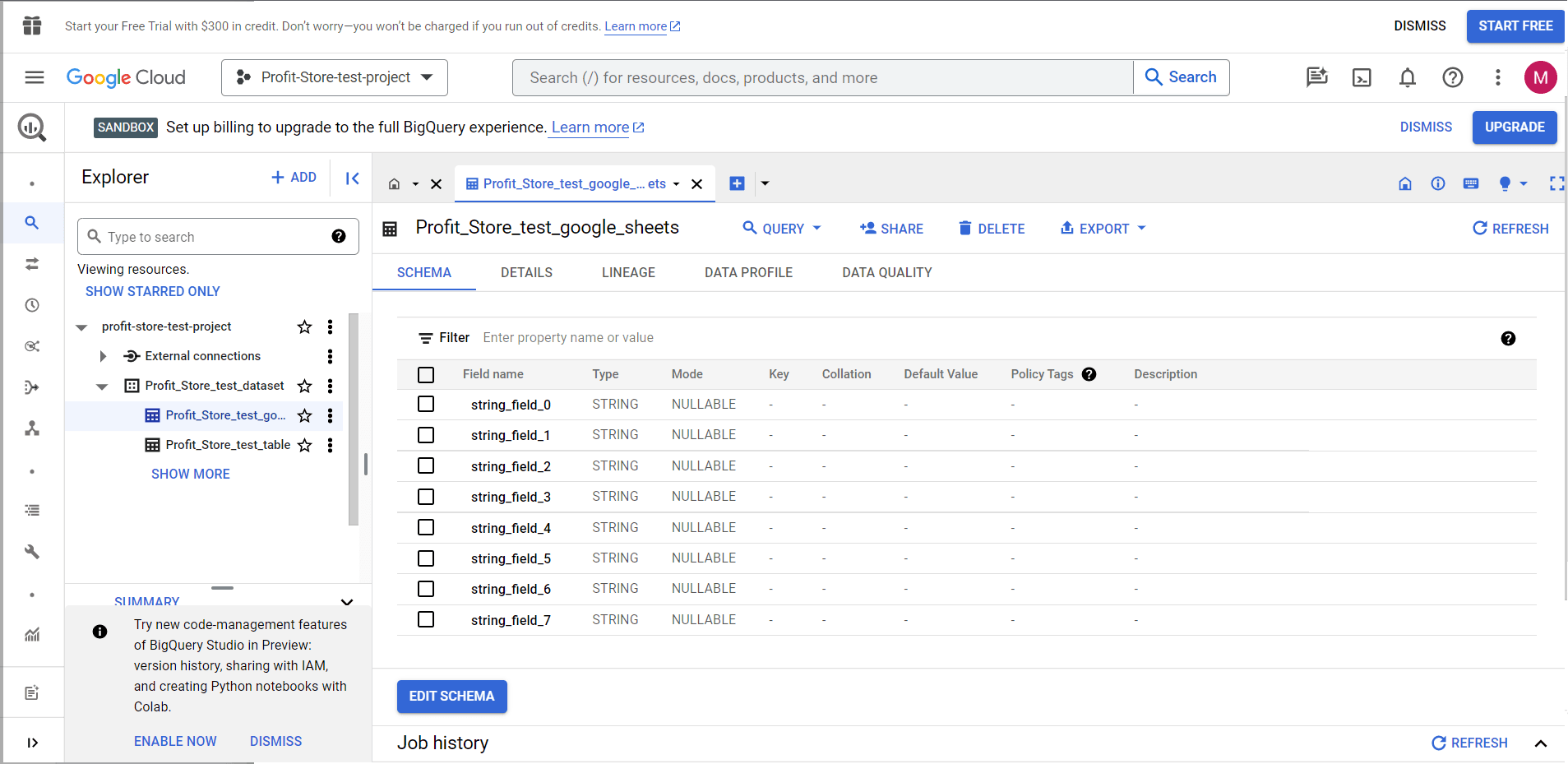
Імпорт даних із джерела в BigQuery
Якщо у вас є набір даних у Airtable, QuickBooks чи іншому джерелі, який плануєте імпортувати в BigQuery, є два основні способи, як це можна зробити: ручний імпорт через CSV або автоматизований імпорт за допомогою ETL-інструментів.
Таблиці запитів у BigQuery
Потужність BigQuery проявляється передусім у обробці запитів. Цей інструмент дозволяє виконувати запити до таблиць бази даних за допомогою універсального SQL-діалекту. Хоча BigQuery також сумісний з нестандартними чи застарілими версіями SQL, рекомендовано застосовувати стандартний діалект SQL.
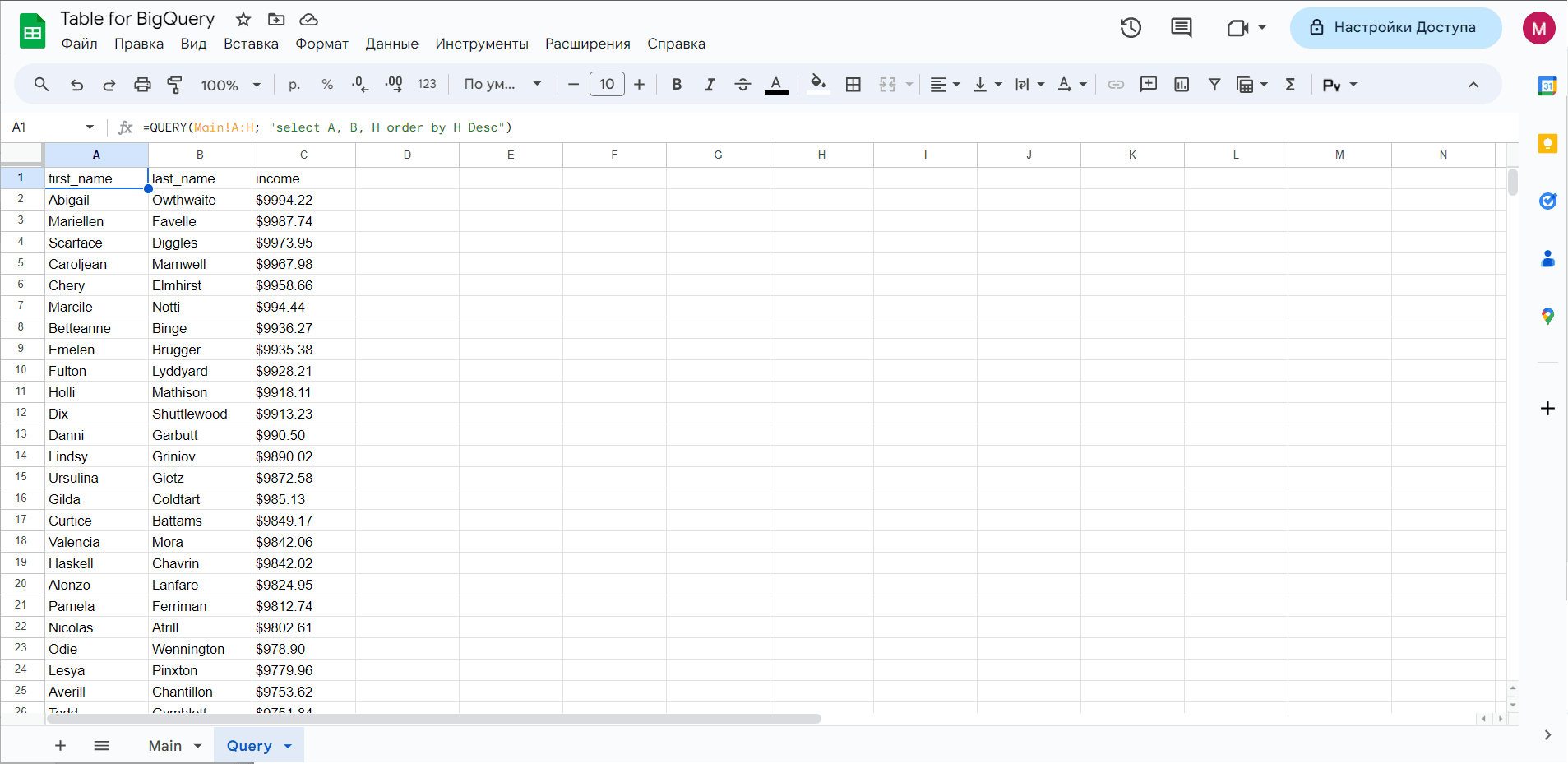
Якщо ви знаєте, який вигляд має функція QUERY в Google Таблицях, ви маєте розуміти, як працюють запити. Наприклад, ось приклад формули QUERY:
=query(Deals!A:EU, "select E, N, T order by T Desc")
"select E, N, T order by T Desc" - це запит для отримання трьох стовпців усього набору даних і впорядкування результатів.
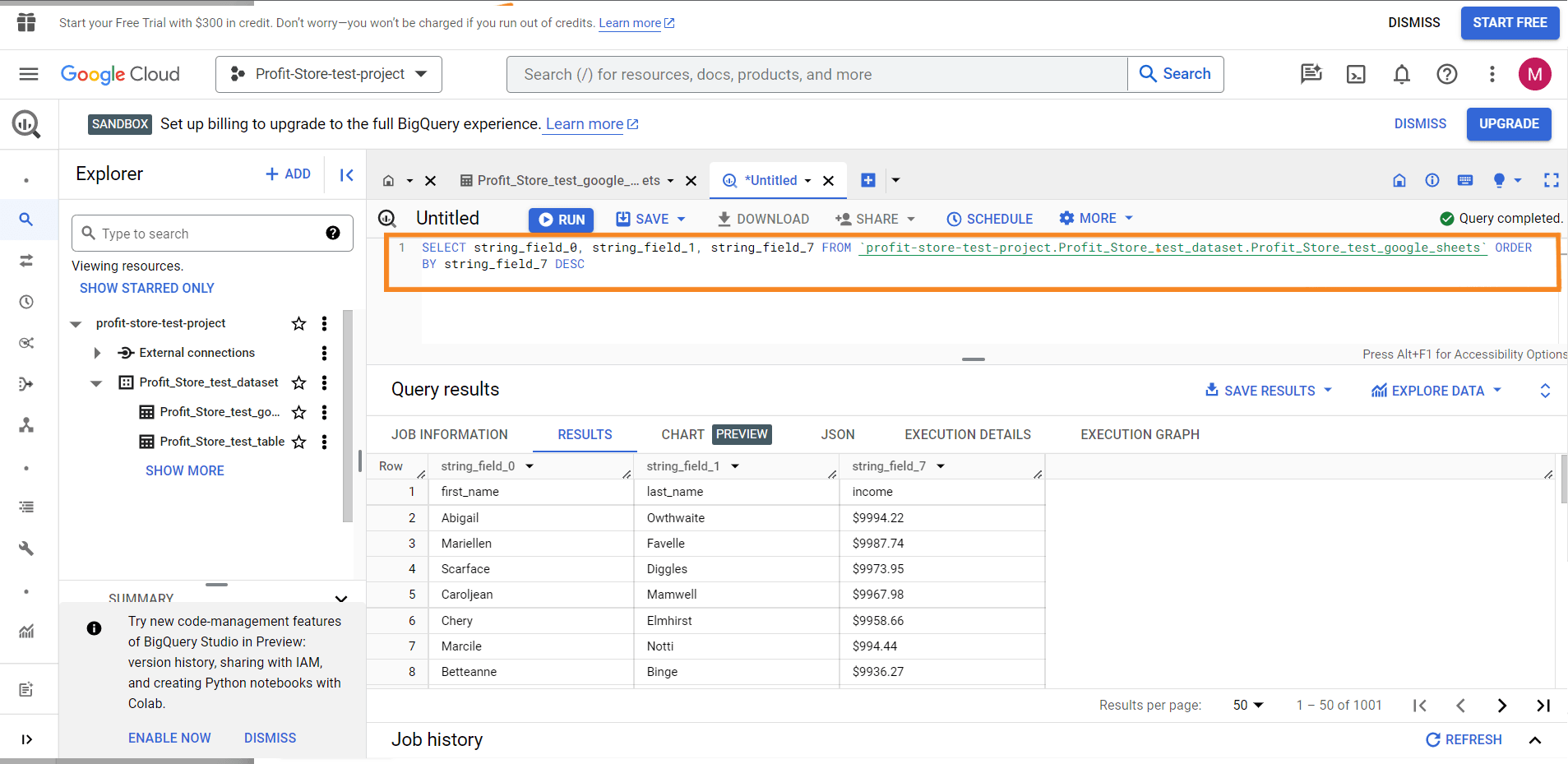
У BigQuery той самий запит до набору даних матиме такий вигляд:
SELECT
string_field_4,
string_field_13,
string_field_19
FROM `test-project-310714.test.pipedrive-deals`
ORDER BY string_field_19 DESC

Тепер пояснимо, як це працює. Як запитувати дані в прикладі синтаксису BigQuery +.
Натисніть кнопку "Таблиця запитів", щоб почати запит.
Ви побачите шаблон запиту, наприклад:
SELECT FROM test-project-310714.test.pipedrive-deals LIMIT 1000
Це основний приклад, який можна використовувати для початку знайомства із запитами. Додайте * після методу SELECT, щоб запит виглядав так:
SELECT * FROM test-project-310714.test.pipedrive-deals LIMIT 1000
Цей запит поверне всі доступні стовпці із зазначеної таблиці, але не більше 1000 рядків. Натисніть "RUN", і все, готово.
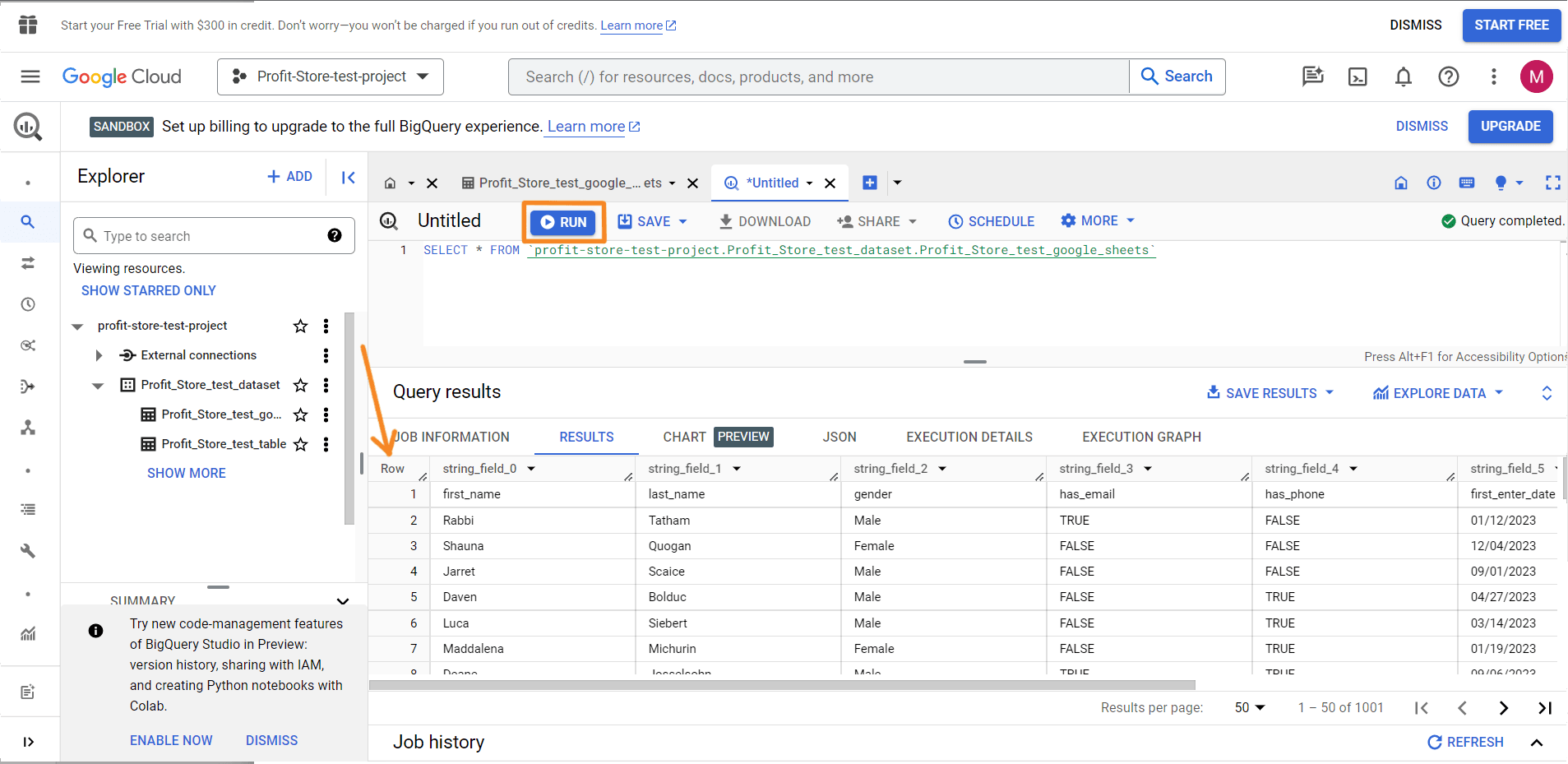
Тепер зробимо запит на певні поля (стовпці) і відсортуємо їх. Отже, замість використання * потрібно вказати потрібні імена полів. Можна знайти імена полів на вкладці "Results" або у своєму останньому запиті.
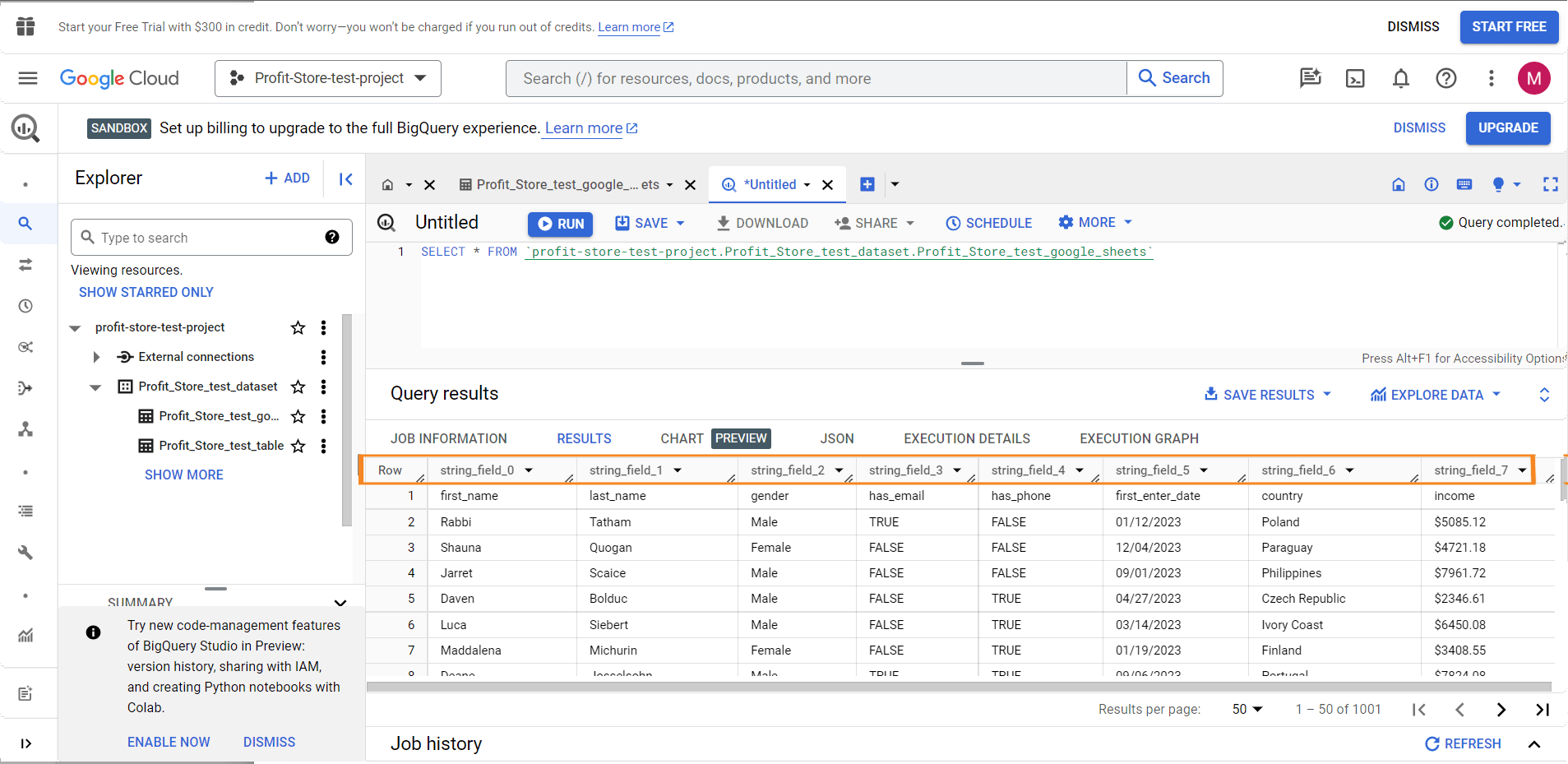
Замінимо метод LIMIT із запиту за замовчуванням на ORDER BY - це дасть змогу сортувати дані за вказаним стовпцем. Щоб впорядкувати дані в порядку убування, додайте DESC в кінець запиту. Ось як це виглядає:
SELECT
string_field_4,
string_field_13,
string_field_19
FROM `test-project-310714.test.pipedrive-deals`
ORDER BY string_field_19 DESC
Налаштування запиту
Якщо натиснути кнопку "MORE" і вибрати налаштування запиту "Query settings", то можна налаштувати місце призначення для результатів запиту, а також інші параметри.
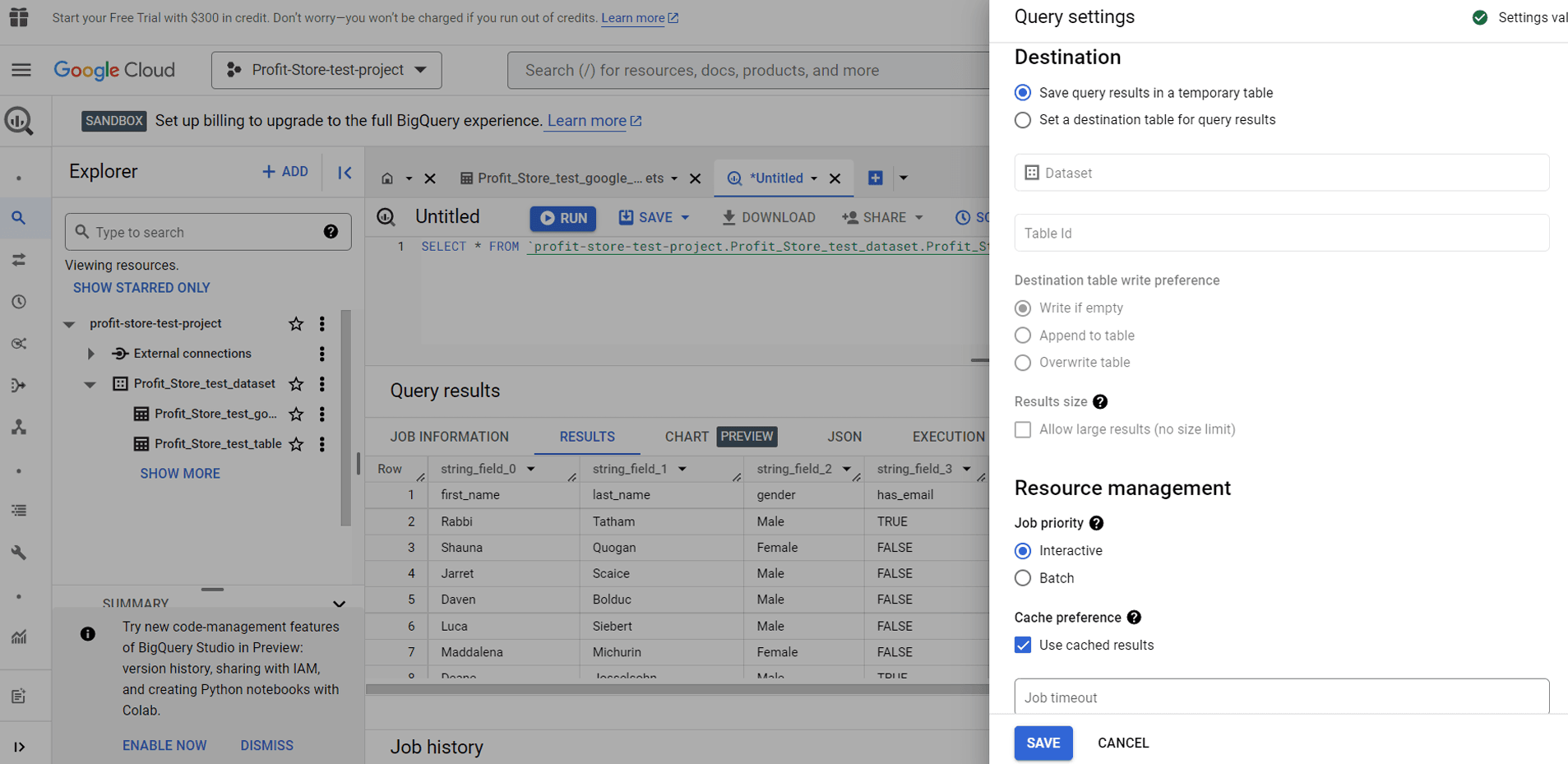
Тут також можна налаштувати запуск запитів у пакетному режимі. Пакетні запити ставляться в чергу і запускаються, щойно в загальному пулі ресурсів BigQuery стають доступні вільні ресурси.
Як зберігати запити в BigQuery
Можна зберегти свої запити для подальшого використання. Для цього натисніть "Save" => "Save Query".
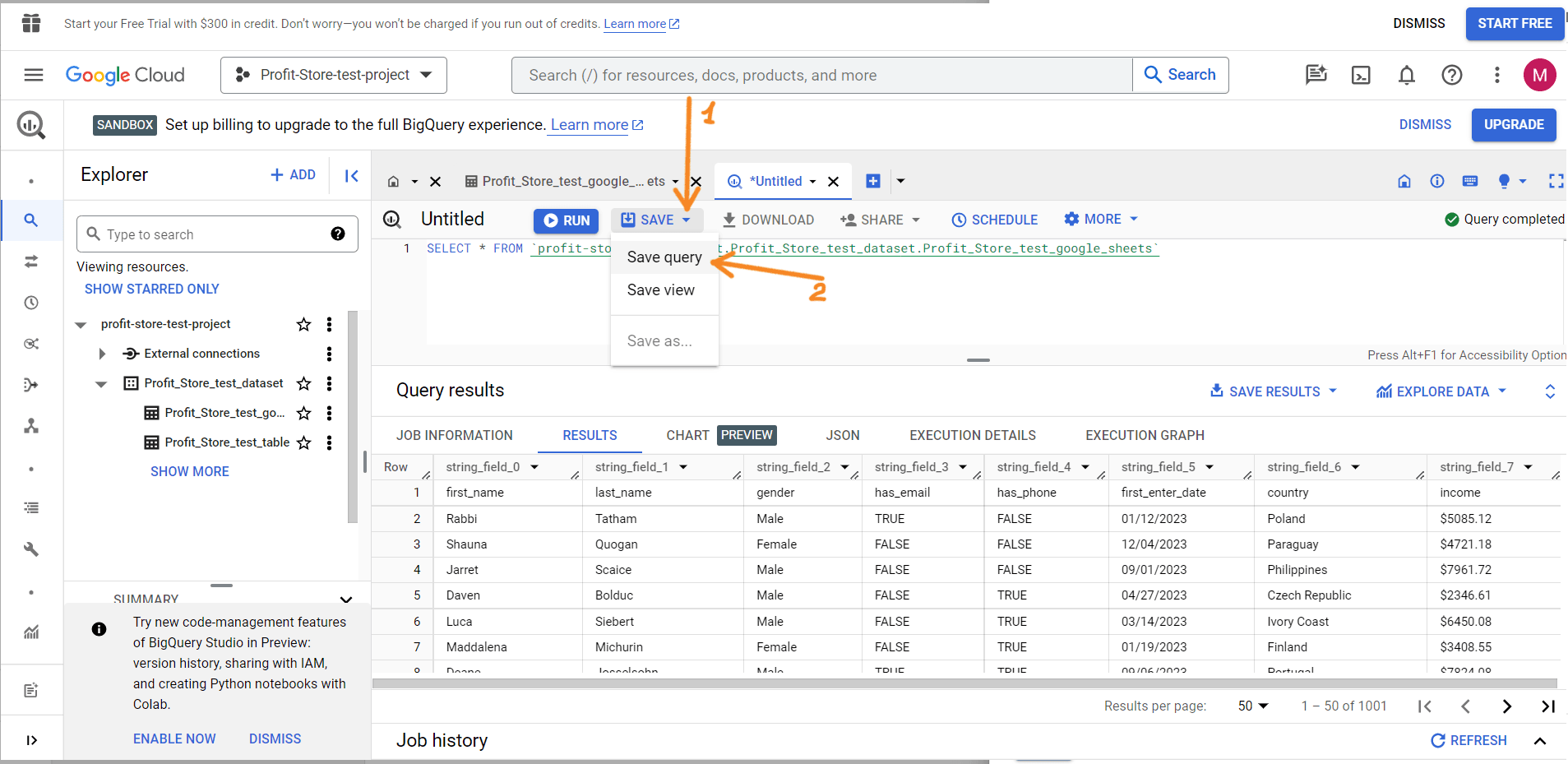
У наступному вікні назвіть свій запит і вкажіть його видимість:
- особисті - тільки ви можете редагувати запит;
- проєкт - тільки учасники проєкту можуть редагувати запит;
- публічний - запит буде загальнодоступним для редагування.
- Збережіть "SAVE".
Як планувати запити в BigQuery
Поруч із кнопкою збереження "SAVE" є кнопка "SCHEDULE", яка дає змогу вмикати запити за розкладом.
Для чого вмикати запити за розкладом:
- Запити можуть бути величезними і вимагати багато часу для виконання, тому краще підготувати дані заздалегідь.
- Google стягує плату за запити даних, тому, якщо ви можете оновлювати дані щодня, краще зробити це і використовувати вже підготовлені подання для запиту до них окремо.
Примітка. Планування запитів доступне тільки для проєктів з увімкненим білінгом. Це не працюватиме для проектів облікових записів SANDBOX (ПІСОЧНИЦЯ).
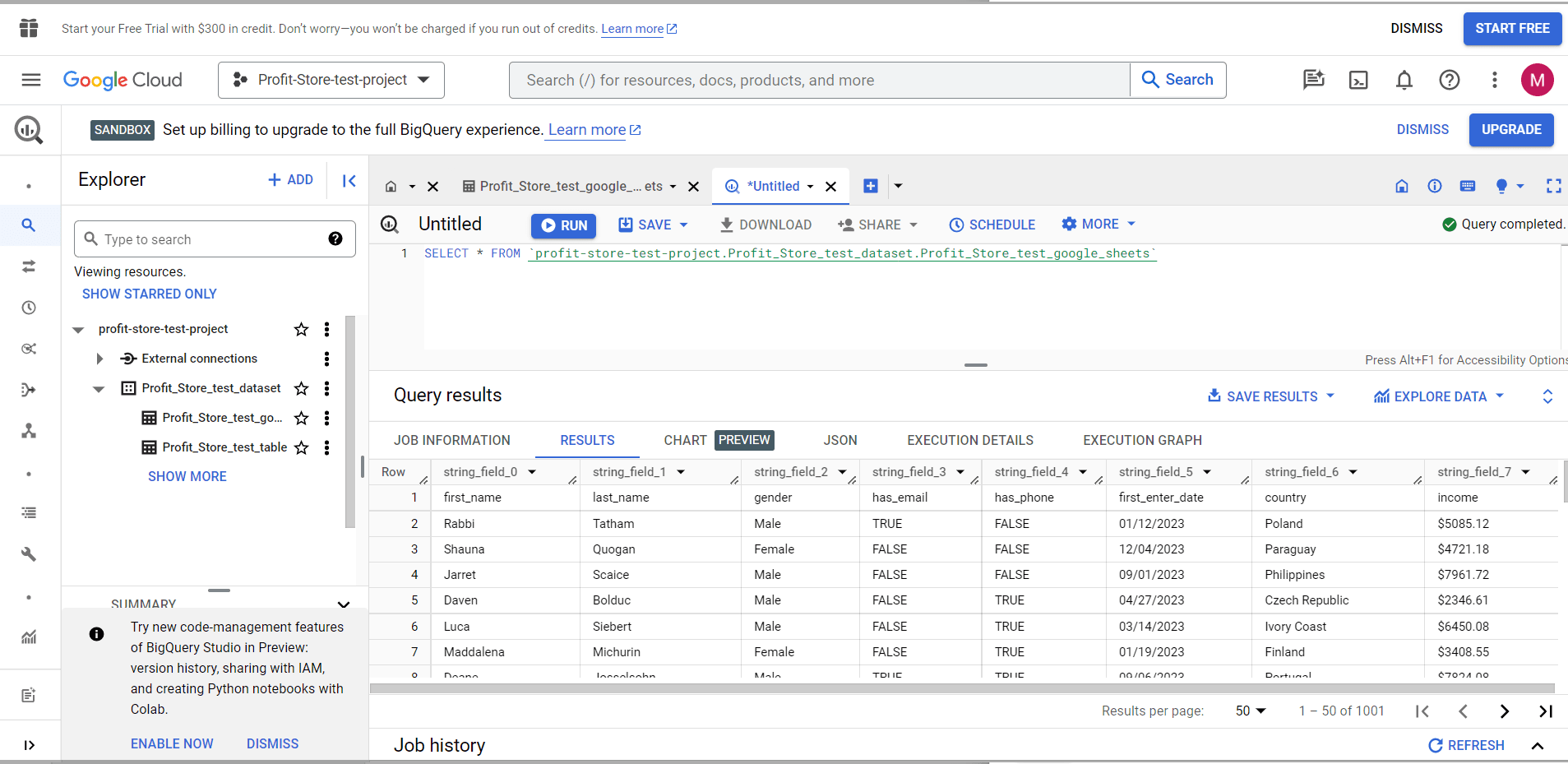
Після натискання кнопки "SCHEDULE", ви отримаєте повідомлення про те, що необхідно спочатку увімкнути BigQuery Data Transfer API.
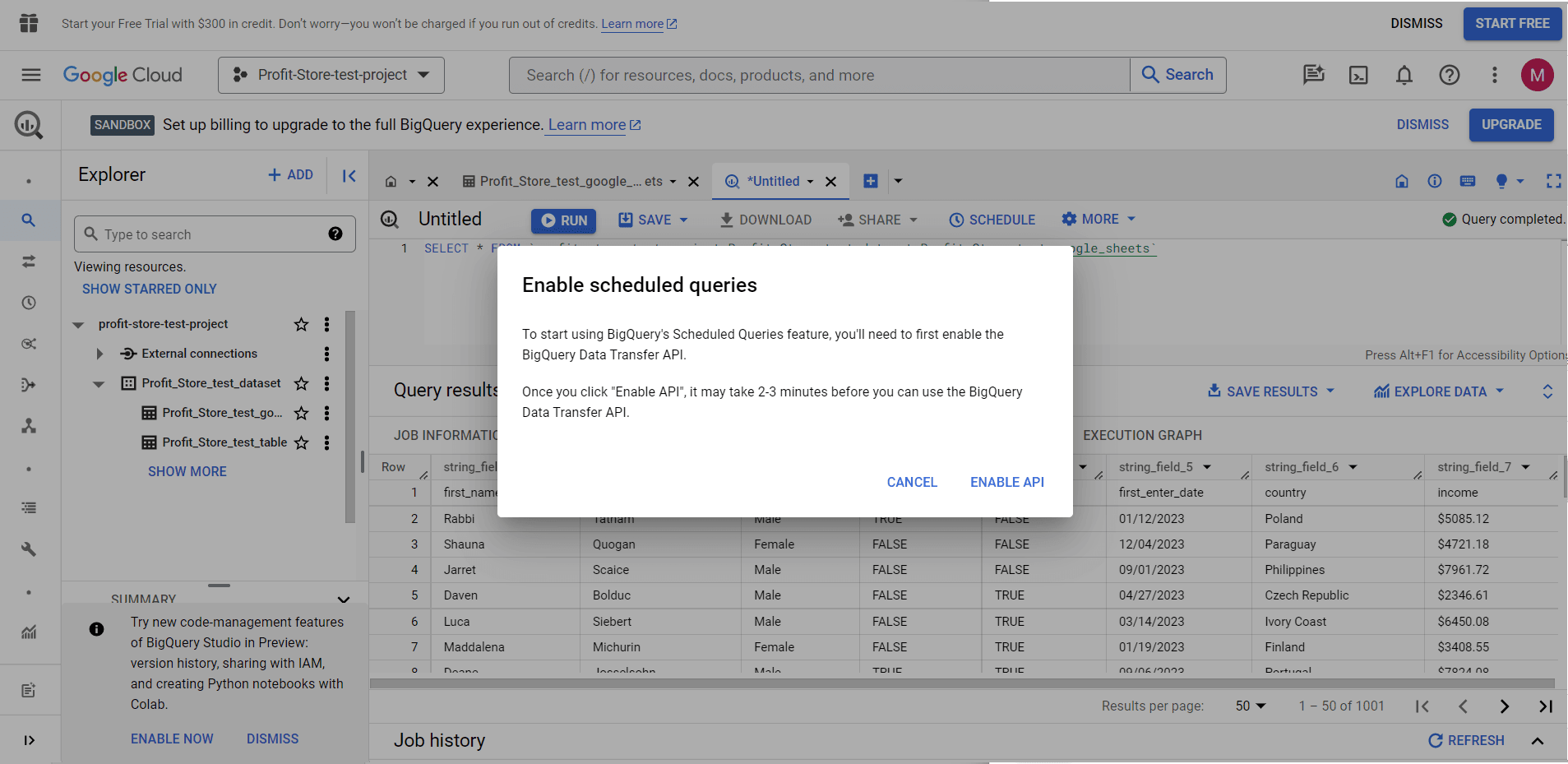
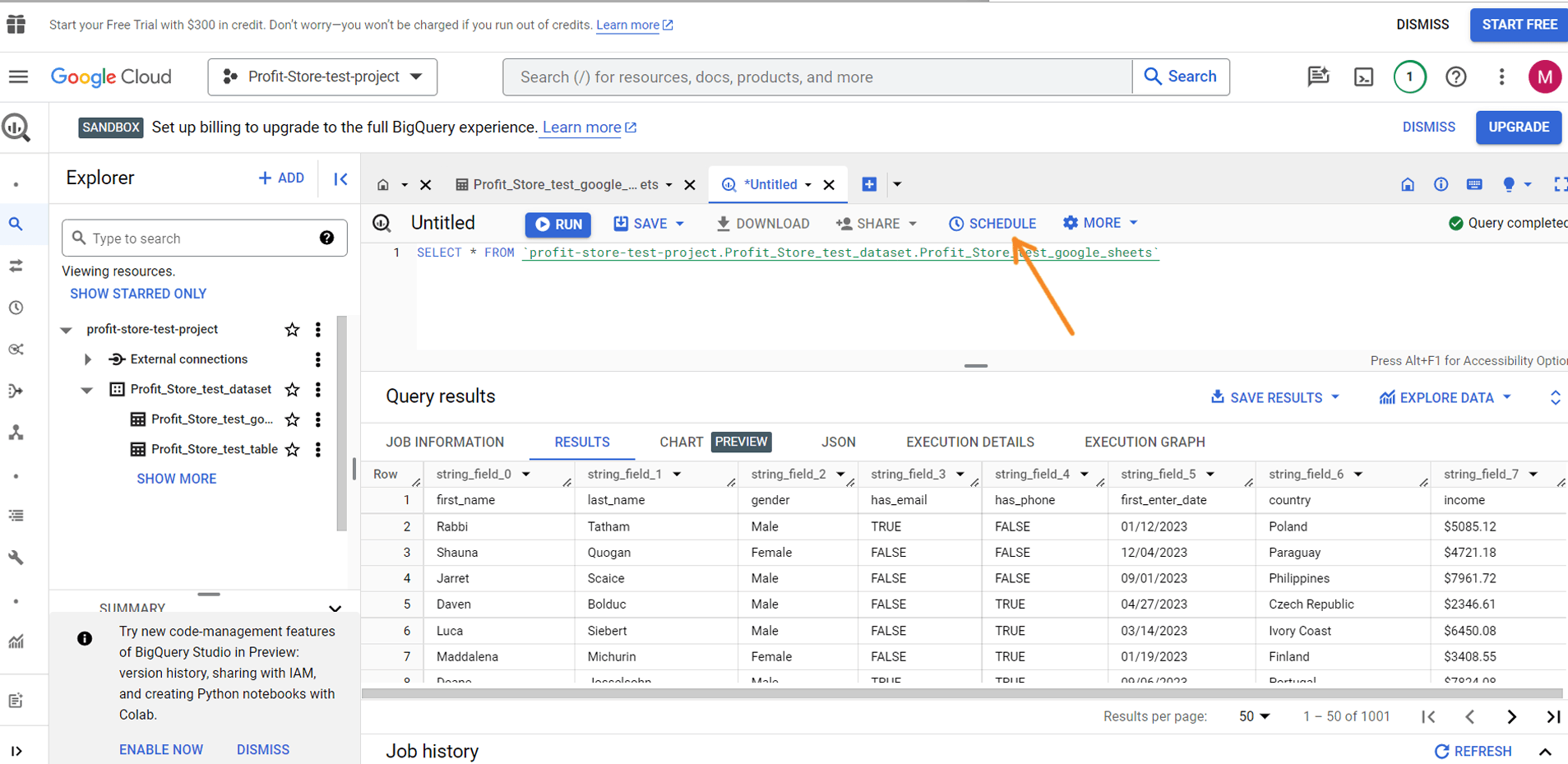
Натисніть "ENABLE API" і почекайте. Після цього можна створювати заплановані запити, натиснувши кнопку "SCHEDULE".
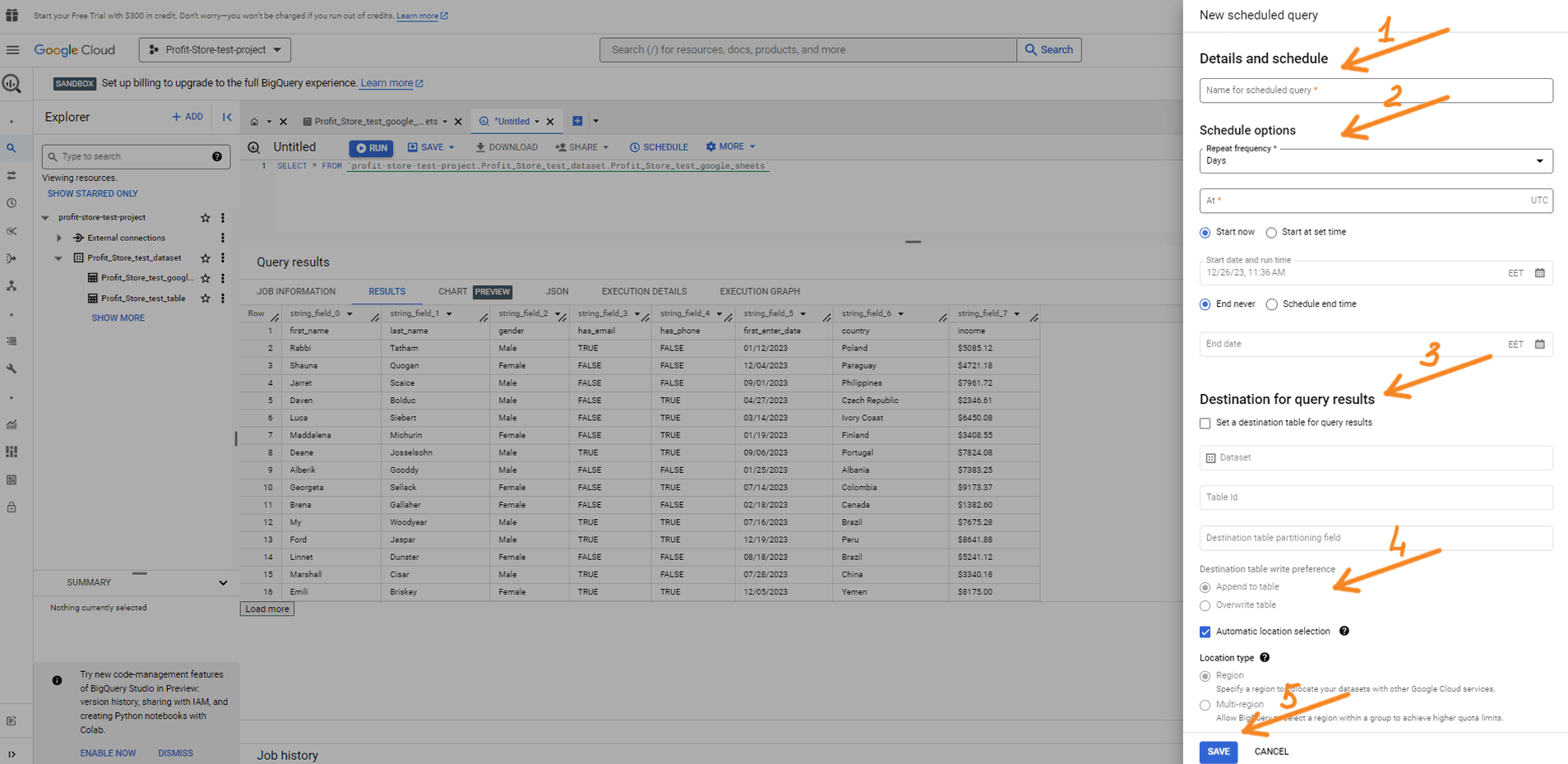
Натисніть "Create new scheduled query" для створення нового запланованого запиту і визначте такі параметри:
- Ім'я запланованого запиту
- Параметри розкладу
- Повторення
- Дата початку і час роботи
- Дата закінчення
- Місце призначення
- Ім'я таблиці
- Запис уподобань (перезапис або додавання)
- Перезаписати - результати запиту перезапишуть дані в таблиці.
- Додати - результати запиту будуть додані до даних у таблиці
За бажання можна налаштувати додаткові параметри та параметри сповіщень. Після завершення налаштування натисніть "Schedule".
Потім потрібно буде вибрати свій обліковий запис Google, щоб продовжити роботу зі службою передачі даних BigQuery.
Історія запитів
Припустимо, ви забули зберегти розширений запит, але хочете відновити його зараз. BigQuery надасть журнали виконаних запитів і завдань. Ви знайдете їх у спливаючих вкладках історії завдань або запитів: "JOB HISTORY" і "QUERY HISTORY".
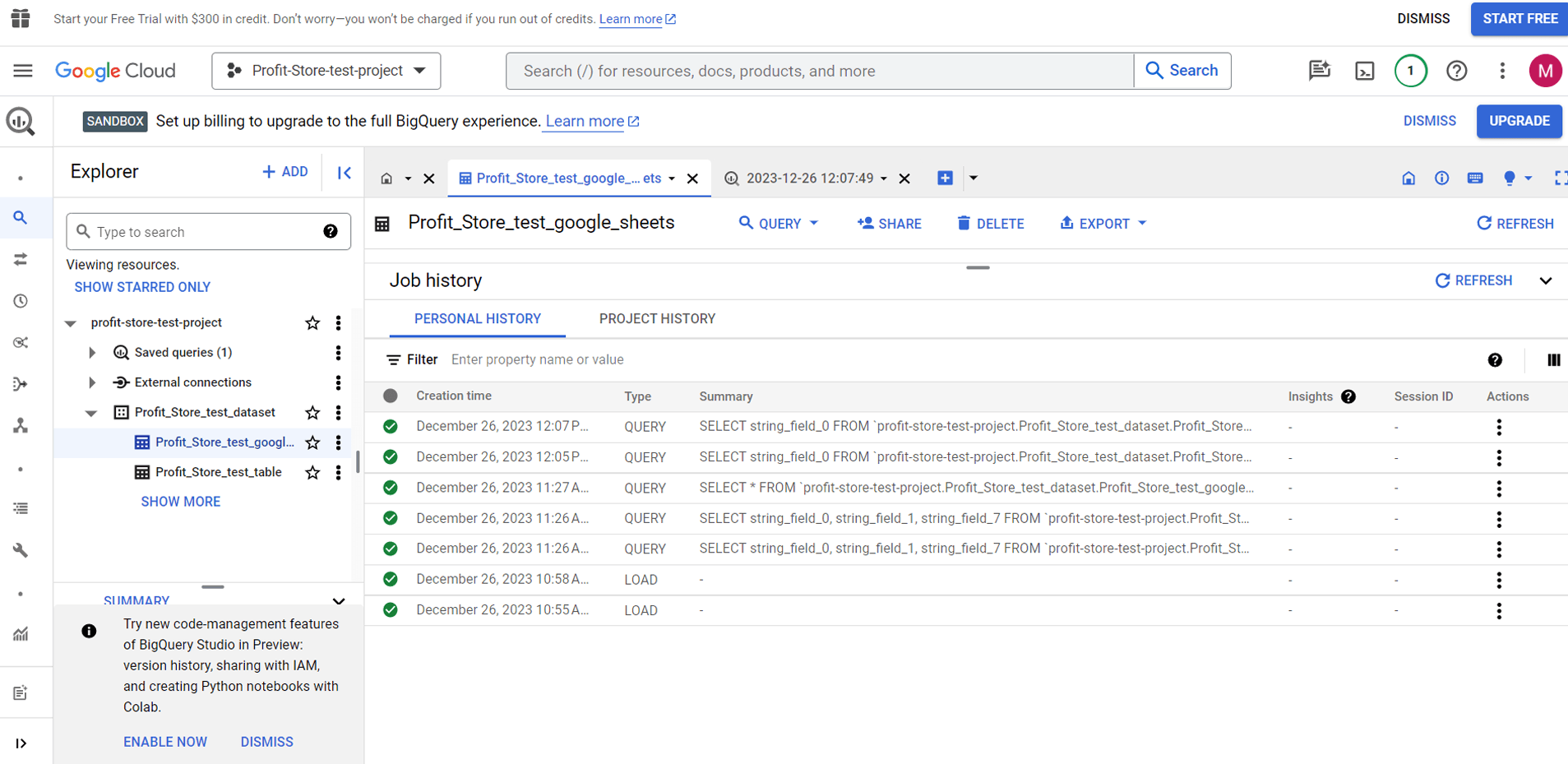
Примітка. BigQuery показує всі операції завантаження, експорту, копіювання та виконання запитів за останні півроку. Однак існує обмеження на кількість збережених записів історії завдань та запитів, яке становить 1000 записів.
Експорт запитів з BigQuery і перенесення даних у BigQuery
Часто користувачам потрібно переносити результати своїх запитів з BigQuery в інші системи. Для цих цілей зазвичай використовують програми для обробки електронних таблиць, наприклад Google Sheets та Microsoft Excel, інструменти для візуалізації даних та дашбордів, такі як Google Looker Studio та Tableau, а також інше програмне забезпечення. До того ж існує можливість з'єднання Power BI з BigQuery.
Щоб експортувати результати запиту, потрібно натиснути кнопку "SAVE QUERY RESULTS" і вибрати один із доступних варіантів:
CSV файл
- Завантажити на свій пристрій (до 16К рядків)
- Завантажити на Google Диск (до 1 ГБ)
JSON файл
- Завантажити на свій пристрій (до 16К рядків)
- Завантажити на Google Диск (до 1 ГБ)
BigQuery таблиця
- Google таблиці (до 16K рядків)
- Копіювати в буфер обміну (до 16K рядків)
Як приклад виберемо параметр таблиці BigQuery. Потрібно буде вибрати проєкт і набір даних, а також назвати таблицю.
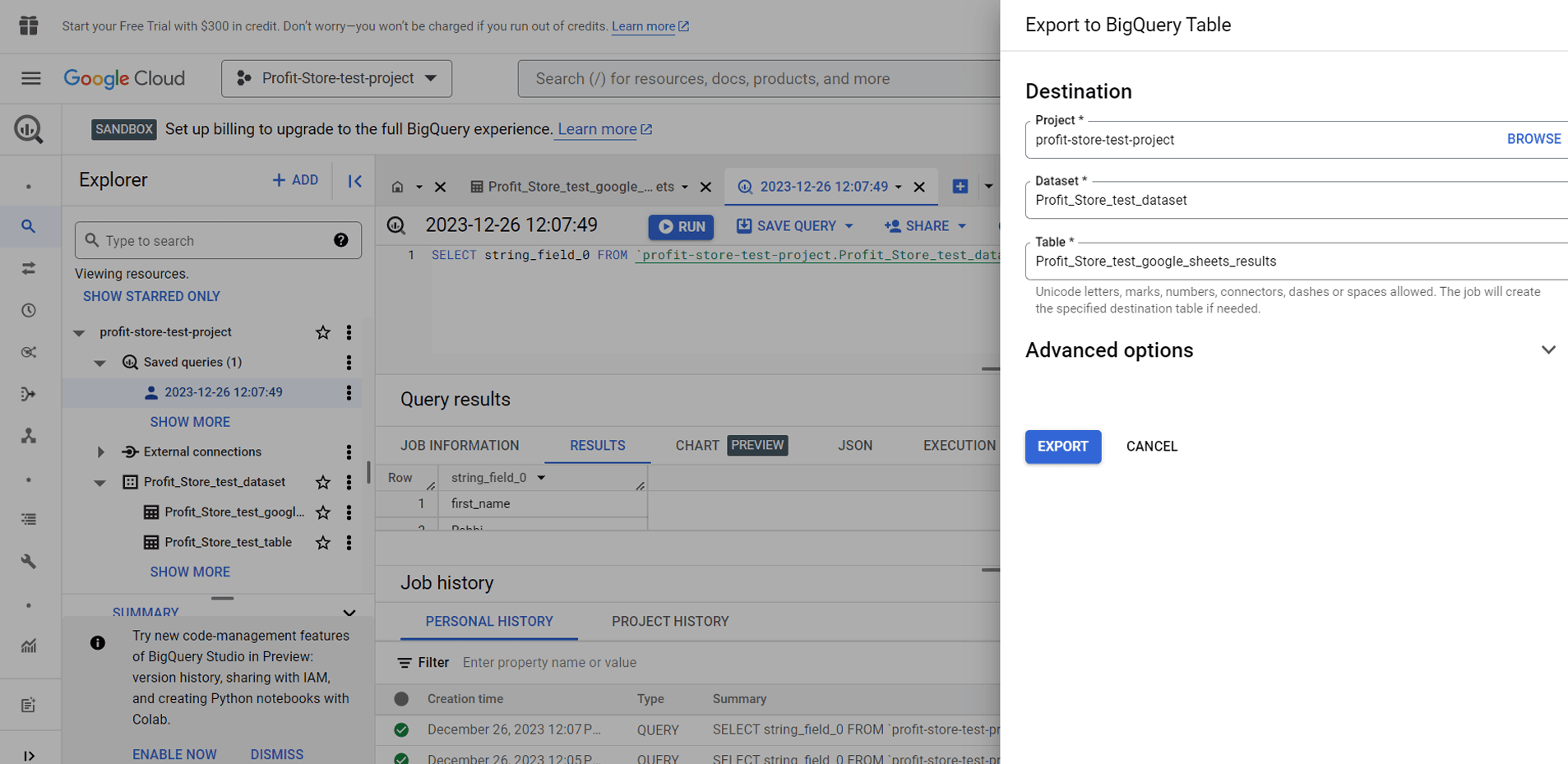
Натисніть "SAVE", і готово.
Як BigQuery зберігає дані
На відміну від традиційних баз даних, де дані розміщуються в порядку рядків, BigQuery використовує стовпчасте зберігання даних. Це означає, що кожен стовпець зберігається у власному файловому блоці. Такий формат зберігання, відомий як Capacitor, забезпечує високу пропускну здатність в BigQuery, що є ключовим аспектом для ефективного онлайн-аналітичного процесу обробки даних.
Архітектура BigQuery
В архітектурі BigQuery ресурси для зберігання та обчислень функціонують окремо. Ця особливість дозволяє завантажувати дані незалежно від їхнього обсягу прямо у систему зберігання і відразу ж приступати до їх аналізу, без зайвих затримок або потреби у попередньому розподілі обчислювальних ресурсів.
Ось інфраструктурні технології, завдяки яким це відбувається:
- Colossus - відповідає за зберігання. Colossus представляє собою глобальну систему зберігання даних, спеціалізовану на ефективному читанні масивних обсягів структурованих даних. Окрім цього, вона виконує завдання реплікації даних, їх відновлення та розподіленого управлінняє.
- Dremel - відповідає за обчислення. Це - мультитенантний кластер, який перетворює SQL-запити на деревоподібні структури виконання. У цих деревах присутні елементи, відомі як "слоти", які функціонують як основні вузли обчислення. Користувач може отримати тисячі слотів для виконання запитів.
- Jupiter відіграє ключову роль у BigQuery, забезпечуючи швидке переміщення даних між сховищем даних (Colossus) та обчислювальною системою (Dremel). Ця система представляє собою мережу петабітного класу, яка здатна пересувати великі обсяги даних з одного місця в інше дуже ефективно і швидко, оптимізуючи загальну продуктивність обробки запитів у BigQuery.
- Borg - відповідає за розподіл апаратних ресурсів. Це система управління кластером для виконання сотень тисяч завдань у BigQuery.
ПОДІЛИТИСЯ

ІНШІ СТАТТІ ВІД АВТОРА
Дізнавайтеся першими про найцікавіше!
Експертні статті, інтерв’ю з підприєцями і СЕО, дослідження, аналітика і огляди сервісів – будьте у курсі новин і трендів у бізнесі та технологіях. Підписуйтеся на розсилку!
Натискаючи «Підписатися», ви погоджуєтеся з Політикою конфіденційності та даєте згоду на використання ваших контактних даних для розсилки новин
АБО СЛІДКУЙ ЗА НАМИ У:
